
Alertmanager告警系统
一、Alertmanager简介
Alertmanager是什么?
Alertmanager是Prometheus官方的告警管理组件,用来接收、处理、去重、分组、静默和路由 Prometheus产生的告警,并将其发送到各种通知渠道(如:Email、Slack、企业微信、钉钉、PagerDuty等)。
Alertmanager的核心功能
- 告警接收与管理:接收来自Prometheus的告警事件(通过HTTP API)。
- 分组(Grouping):将相似告警(例如同一服务多个实例宕机)合并成一条通知,避免信息洪水。
- 去重(Deduplication):对同一个告警在重复触发时去重,只保留一条活跃告警。
- 抑制(Inhibition):可以定义规则:当某个告警触发时,自动抑制其他相关告警(避免重复通知)。比如:如果整个节点宕机,就不再报警说"CPU使用率过高"。
- 静默(Silences):临时屏蔽某些告警,不会发送通知(常用于维护期间)。
- 路由(Routing):根据告警的标签(如:severity=critical、team=ops)决定通知发往哪个接收器。
- 通知(Notification):将处理后的告警发送到配置好的接收器,如:Email、Slack、微信、钉钉、PagerDuty、Webhook 等。
二、安装Alertmanager
普通安装
下载并解压安装包
# 下载安装包
wget https://github.com/prometheus/alertmanager/releases/download/v0.27.0/alertmanager-0.27.0.linux-amd64.tar.gz
# 解压,并将目录移动修改名字
tar -xvf alertmanager-0.27.0.linux-amd64.tar.gz
mv alertmanager-0.27.0.linux-amd64 /usr/local/alertmanager
配置一个简单的配置文件,先不配置任何通知方式,如下所示:
# /usr/local/alertmanager/alertmanager.yml
global:
resolve_timeout: 5m # 告警恢复等待时间,默认 5 分钟
route:
# 告警路由配置
group_by: ['alertname'] # 按 alertname 分组
group_wait: 30s # 等待 30 秒再发送分组告警
group_interval: 5m # 相同分组的告警,最小发送间隔
repeat_interval: 1h # 告警重复发送的时间间隔
receiver: 'default-receiver' # 默认接收器
receivers:
- name: 'default-receiver'
到服务目录下启动服务
cd /usr/local/alertmanager
./alertmanager --config.file=alertmanager.yml
或者设置systemd服务管理(可选)
# 增加systemd配置文件
cat > /etc/systemd/system/alertmanager.service << EOF
[Unit]
Description=Prometheus Alertmanager
After=network.target
[Service]
User=prometheus
ExecStart=/usr/local/alertmanager/alertmanager \
--config.file=/usr/local/alertmanager/alertmanager.yml \
--storage.path=/usr/local/alertmanager/data
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
# 启动服务
systemctl daemon-reload
systemctl enable alertmanager --now
docker安装
创建alertmanager的工作目录。
mkdir -p /data/alertmanager
在工作目录下编辑compose文件。
# /data/alertmanager/docker-compose.yaml
alertmanager:
image: prom/alertmanager:v0.28.1
container_name: alertmanager
restart: unless-stopped
command:
- --config.file=/etc/alertmanager/alertmanager.yml
- --storage.path=/alertmanager
ports:
- 9093:9093
volumes:
- ./alertmanager.yml:/etc/alertmanager/alertmanager.yml
使用docker compose启动服务。
docker compose up -d
访问测试
我们可以直接地址+端口的形式访问Web页面,我的地址是localhost:9093,如下图所示:
三、告警配置
告警规则
添加告警规则
修改Prometheus服务的配置文件,添加规则文件路径。如下所示:
rule_files:
- "/etc/prometheus/first_rules.yml"
- "second_rules.yml"
- "rules/*.yml"
温馨提示:规则文件的配置可以是绝对路径和相对路径两种方式。
规则格式
一个简单的规则文件格式,如下所示:
groups:
- name: group_name # 告警规则组的名字
interval: 30s # (可选)该组内规则的评估周期,默认和全局 evaluation_interval 一致
rules: # 告警规则列表
- alert: AlertName # 告警名称(必填)
expr: expression # PromQL 表达式,决定何时触发告警(必填)
for: 2m # (可选)持续多长时间满足条件才触发告警
labels: # (可选)自定义标签,附加到告警上
severity: warning
team: ops
annotations: # (可选)附加说明,用于通知时显示详细信息
summary: "简短描述"
description: "详细描述,可以包含 {{ $labels.xxx }} 占位符"
字段属性说明:
group:表示告警规则组,可以有多个,每个group下包含若干条rules。name:每个告警规则组必须有的名字。interval:该组内规则的评估周期,如果没写,默认用Prometheus全局配置evaluation_interval(一般是 15s)。rules:规则列表,里面写具体的告警规则,下面包含多个alert告警规则。alert:告警规则的名称。expr:核心部分,用于进行报警规则PromQL查询语句,当表达式结果为非零值或true时,触发告警。for:评估等待时间(Pending Duration),用于表示只有当触发条件持续一段时间后才发送告警,在等待期间新产生的告警状态为pending。labels:自定义标签,允许用户指定额外的标签列表,把它们附加在告警上。annotations:指定了另一组标签,它们不被当做告警实例的身份标识,它们经常用于存储一些额外的信息,用于报警信息的展示之类的。
告警信息声明周期的3种状态:
pending: 表示在设置的阈值时间范围内被激活了。firing: 表示超过设置的阈值时间被激活了。inactive: 报警规则没有得到满足或者已经过期(还没触发或者已经修复)。
告警接收器
告警通知的方式有很多,比如:Email、Slack、Webhook、企业微信、钉钉等。
定义接收器
主要由route和receivers两个部分组成,在route模块中配置路由规则,指定默认的接收器,在receivers模块中配置所需要的接收器。
route字段含义:
receiver:该路由匹配到告警后默认要发送到的接收器。group_by: 决定如何把告警分组为一条通知(一般用 [‘alertname’,‘instance’])。group_wait: 新分组首次等待时间(把短时间内的相关告警聚合再发)。group_interval: 相同分组内再次发送前的最小间隔(防止频繁推送)。repeat_interval: 当告警一直存在时,重复发送整组告警的间隔。routes: 子路由数组,用来基于标签把告警精细路由到不同接收器。matchers: 按告警标签过滤匹配(支持等于、不等、正则等操作)。continue: 如果 true,在当前节点匹配后仍继续尝试后面的兄弟路由(用于同时发到多个接收目标);默认 false。
注意:matchers以前旧的写法是match和match_re,推荐用新的写法
route常见写法:
route:
receiver: 'default'
group_by: ['alertname']
group_wait: 30s
group_interval: 5m
repeat_interval: 1h
每个receiver是一组通知集成(可以在一个 receiver 下同时配置 email、slack、webhook等多种*_configs)。发送时Alertmanager会把告警发送到该receiver中定义的所有配置。
receivers常见写法:
receivers:
- name: 'default'
email_configs:
......
slack_configs:
......
接收器选择
我们可以使用route模块下的routes进行配置规则选择接收器,如下所示:
route:
receiver: 'default'
group_by: ['alertname','instance']
group_wait: 30s
group_interval: 5m
repeat_interval: 2h
routes:
- matchers: # 紧急:直接上 PagerDuty,并继续让其他路由也处理(比如 Slack)
- 'severity="critical"'
receiver: 'critical-receiver'
continue: true
- matchers: # 发给对应 team 的协作渠道
- 'team="ops"'
receiver: 'ops-receiver'
receivers:
# 默认的接收器,发送slack
- name: 'default'
slack_configs:
- channel: '#ops'
text: '{{ template "slack.msg" . }}'
# critical-receiver接收器,同时发送webhook和email
- name: 'critical-receiver' # PagerDuty(用于紧急值班)
webhook_configs: # 通用 webhook(用于钉钉/企业微信/内部系统)
- url: 'https://example.com/webhook'
max_alerts: 50
email_configs:
- to: 'ops@example.com'
# ops-receiver接收器,发送slack
- name: 'ops-receiver'
slack_configs:
- channel: '#ops'
text: '{{ template "slack.msg" . }}'
我们可以同时配置多个接收器,然后在route中根据标签配置规则来选择接收器通知。
告警通知模板
先编写一个邮件的告警模板文件/usr/local/alertmanager/templates/email_template.tmpl。内容如下:
{{ define "email.html" }}
{{- if gt (len .Alerts.Firing) 0 -}}{{ range .Alerts }}
@报警<br>
<strong>实例:</strong> {{ .Labels.instance }}<br>
<strong>概述:</strong> {{ .Annotations.summary }}<br>
<strong>详情:</strong> {{ .Annotations.description }}<br>
<strong>时间:</strong> {{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}<br>
{{ end }}{{ end -}}<br>
{{- if gt (len .Alerts.Resolved) 0 -}}{{ range .Alerts }}<br>
@恢复<br>
<strong>实例:</strong> {{ .Labels.instance }}<br>
<strong>信息:</strong> {{ .Annotations.summary }}<br>
<strong>恢复:</strong> {{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}<br>
{{ end }}{{ end -}}
{{- end }}
在配置文件中导入并在接收器中引用模板,修改Alertmanager服务配置文件,如下所示:
# 导入通知模板
templates:
- 'templates/email_template.tmpl'
receivers:
- name: 'email'
email_configs:
......
html: '{{ template "email.html" . }}'
常见接收器示例
receivers:
- name: 'email'
email_configs:
- to: 'oncall@example.com' # 必填:收件人(可用逗号分隔多个)
from: 'alertmanager@example.com' # 可选(也可在 global 里设置)
smarthost: 'smtp.example.com:587' # 必填或 global
auth_username: 'alertmanager' # 如需认证
auth_password: 'supersecret' # 或使用 auth_password_file
require_tls: true
send_resolved: true
html: '{{ template "email.default.html" . }}' # 支持模板的字段 (示例)
Slack
global:
slack_api_url: 'https://hooks.slack.com/services/AAA/BBB/CCC'
receivers:
- name: 'slack'
slack_configs:
- channel: '#alerts'
username: 'alertmanager'
title: '{{ .CommonLabels.alertname }} on {{ .CommonLabels.instance }}'
text: '{{ template "slack.default" . }}'
send_resolved: true
Webhook
receivers:
- name: 'webhook'
webhook_configs:
- url: 'http://webhook地址'
send_resolved: true
max_alerts: 50 # 可选:单次推送最大告警数,防止 payload 太大
http_config:
bearer_token: 'xxxxx' # 如需 basic auth / bearer token / TLS 设置
四、告警配置步骤
1.配置告警规则文件
在Prometheus服务中配置告警规则文件,先在Prometheus的目录下创建一个rules目录,再新增规则文件。比如:新增一个node_down_rules.yml规则文件,也就是/prometheus/rules/node_down_rules.yml文件。
# /prometheus/rules/node_down_rules.yml
groups:
- name: NodeDwon-Alerts
rules:
- alert: NodeDwon
expr: up == 0
for: 1m
labels:
severity: warning
annotations:
summary: "节点{{ $labels.instance }}已停止工作"
description: "{{ $labels.job }} 分组下的节点 {{ $labels.instance }} 已经挂掉超过1分钟!!!"
2.配置Prometheus配置
在Prometheus配置文件中加载规则并配置Alertmanager地址,也就是修改prometheus.yml文件,将rules目录下所有.yml文件加载成告警规则文件。
# 定义全局配置
global:
scrape_interval: 15s
scrape_timeout: 15s
evaluation_interval: 30s # 默认情况下每分钟对告警规则进行计算
# 配置Alertmanager服务信息
alerting:
alertmanagers:
- static_configs:
- targets:
- "localhost:9093" # Alertmanager 服务地址
# 定义告警规则文件列表放在rules目录下
rule_files:
- "rules/*.yml"
3.配置Alertmanager服务
配置配置Alertmanager服务的配置文件,也就是alertmanager.yml文件,配置告警处理什么的。
我们这里使用Webhook的方式调用钉钉接口通知。如下所示:
global:
resolve_timeout: 5m # 告警恢复等待时间,默认5分钟
route:
# 告警路由配置
receiver: 'webhook' # 对接webhook接收器
group_by: ['alertname'] # 按 alertname 分组
group_wait: 30s # 等待 30 秒再发送分组告警
group_interval: 5m # 相同分组的告警,最小发送间隔
repeat_interval: 1h # 告警重复发送的时间间隔
receivers:
- name: 'webhook' # 接收器名字
webhook_configs:
- url: 'http://172.16.10.82:8080/webhook' # webhook地址
send_resolved: true
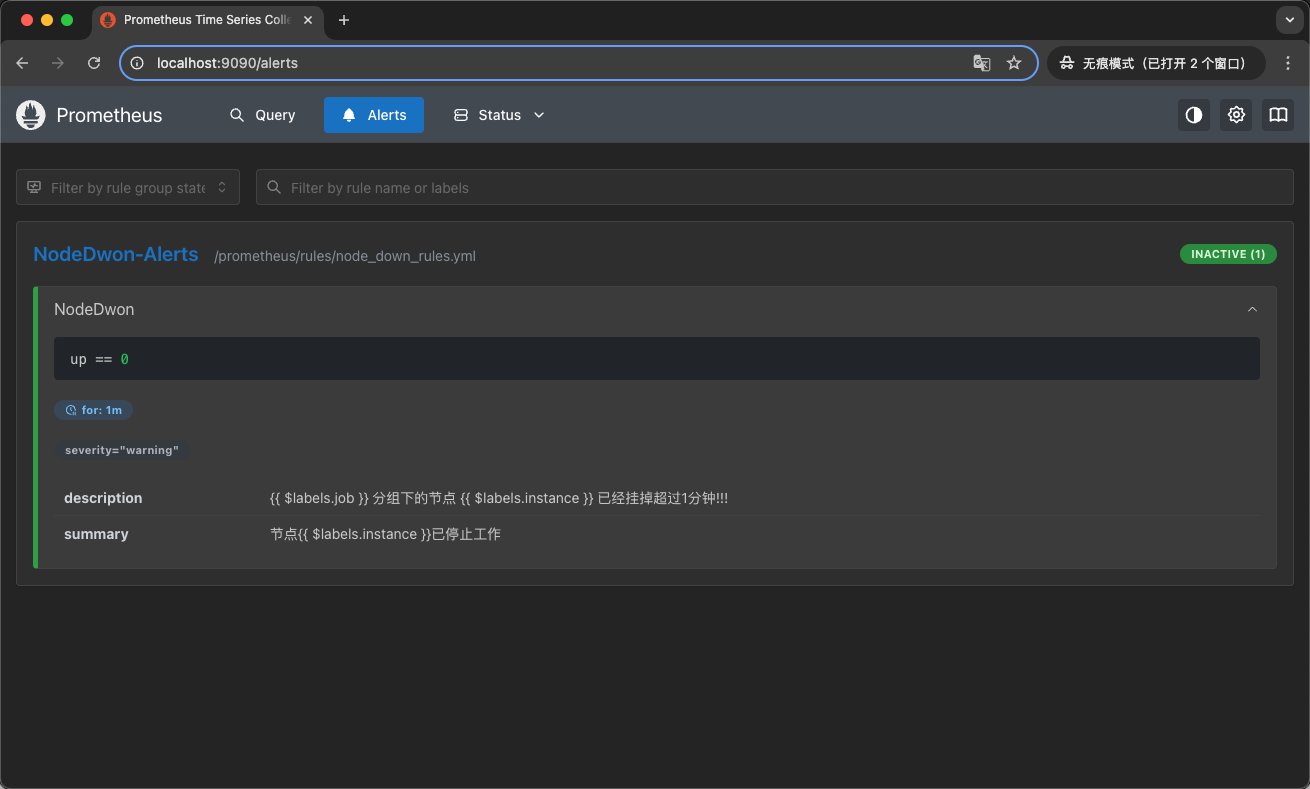
配置成功之后我们能在Prometheus页面看到新增加的规则,如下图所示:
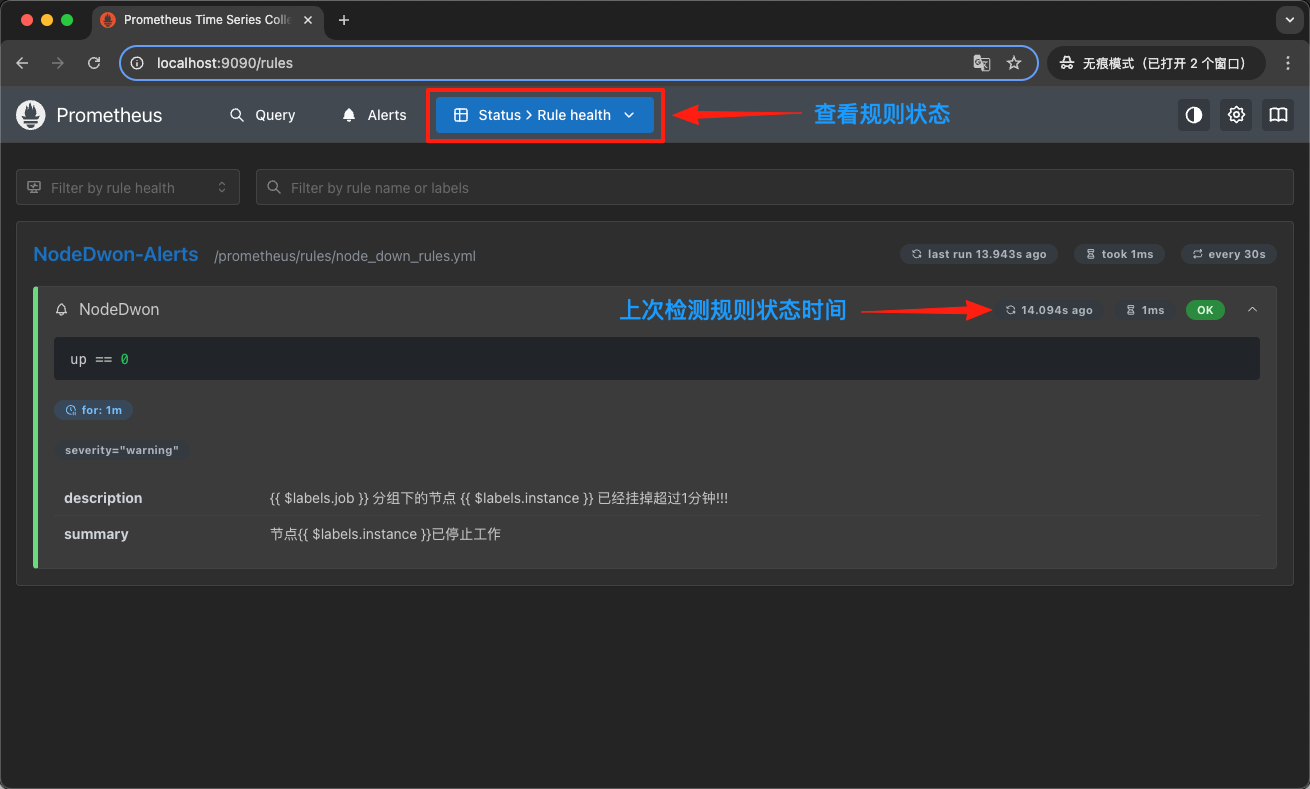
我们还能在状态选项里面查看具体状态,如下图所示:
4.部署Webhook服务
我们这里是自己用Python写的Webhook服务,调用/webhook接口则会调用钉钉接口发送对应的消息。
AlertManager将报警信息使用POST调用的webhook的数据结构如下:
{
"receiver": "webhook",
"status": "firing",
"alerts": [
{
"status": "firing",
"labels": {
"alertname": "NodeDwon",
"instance": "192.168.101.202:9100",
"job": "Node",
"severity": "warning"
},
"annotations": {
"description": "Node 分组下的节点 192.168.101.202:9100 已经挂掉超过1分钟!!!",
"summary": "节点192.168.101.202:9100已停止工作"
},
"startsAt": "2025-09-10T06:17:09.413Z",
"endsAt": "0001-01-01T00:00:00Z",
"generatorURL": "http://fd82ae7fd44f:9090/graph?g0.expr=up%7Bjob%3D%22Node%22%7D+%3D%3D+0&g0.tab=1",
"fingerprint": "4174f415124ca8d8"
}
],
"groupLabels": {
"alertname": "NodeDwon"
},
"commonLabels": {
"alertname": "NodeDwon",
"instance": "192.168.101.202:9100",
"job": "Node",
"severity": "warning"
},
"commonAnnotations": {
"description": "Node 分组下的节点 192.168.101.202:9100 已经挂掉超过1分钟!!!",
"summary": "节点192.168.101.202:9100已停止工作"
},
"externalURL": "http://d10afaf95ec7:9093",
"version": "4",
"groupKey": "{}:{alertname=\"NodeDwon\"}",
"truncatedAlerts": 0
}
也可以使用开源的一些简单Webhook程序,如下所示:
代码仓库地址:https://github.com/cnych/promoter
5.测试告警
我们在服务器任意一个节点上停掉node_exporter服务来模拟宕机进行测试告警是否能够正常告警。
systemctl stop node_exporter
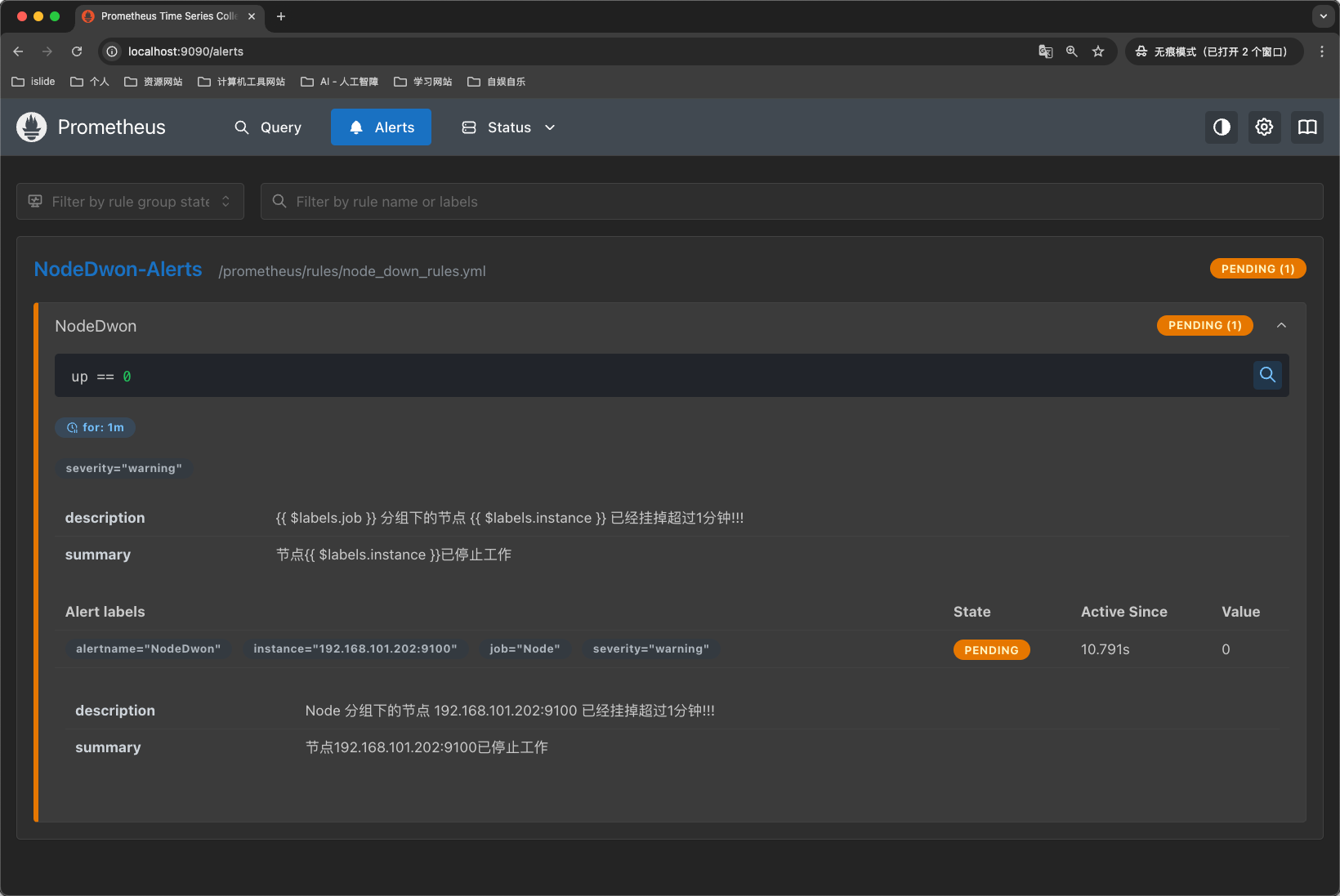
停掉服务之后,再去Prometheus页面查看告警规则的状态,发现状态从健康状态变成了PENDING状态,因为我们设置的是要宕机1分钟时间才会告警,如下图所示:
等过了1分钟,发现状态变成了告警状态,如下图所示:
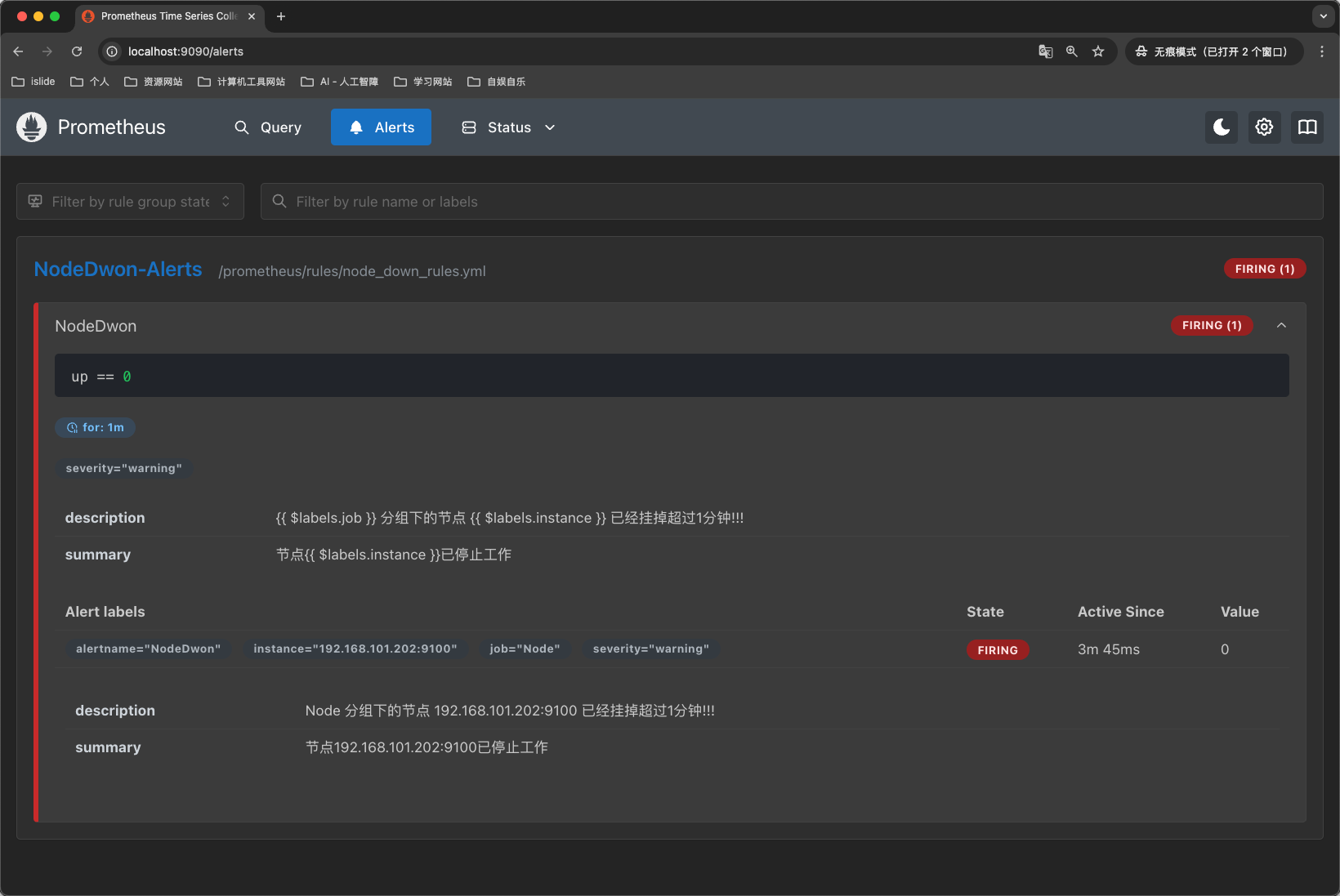
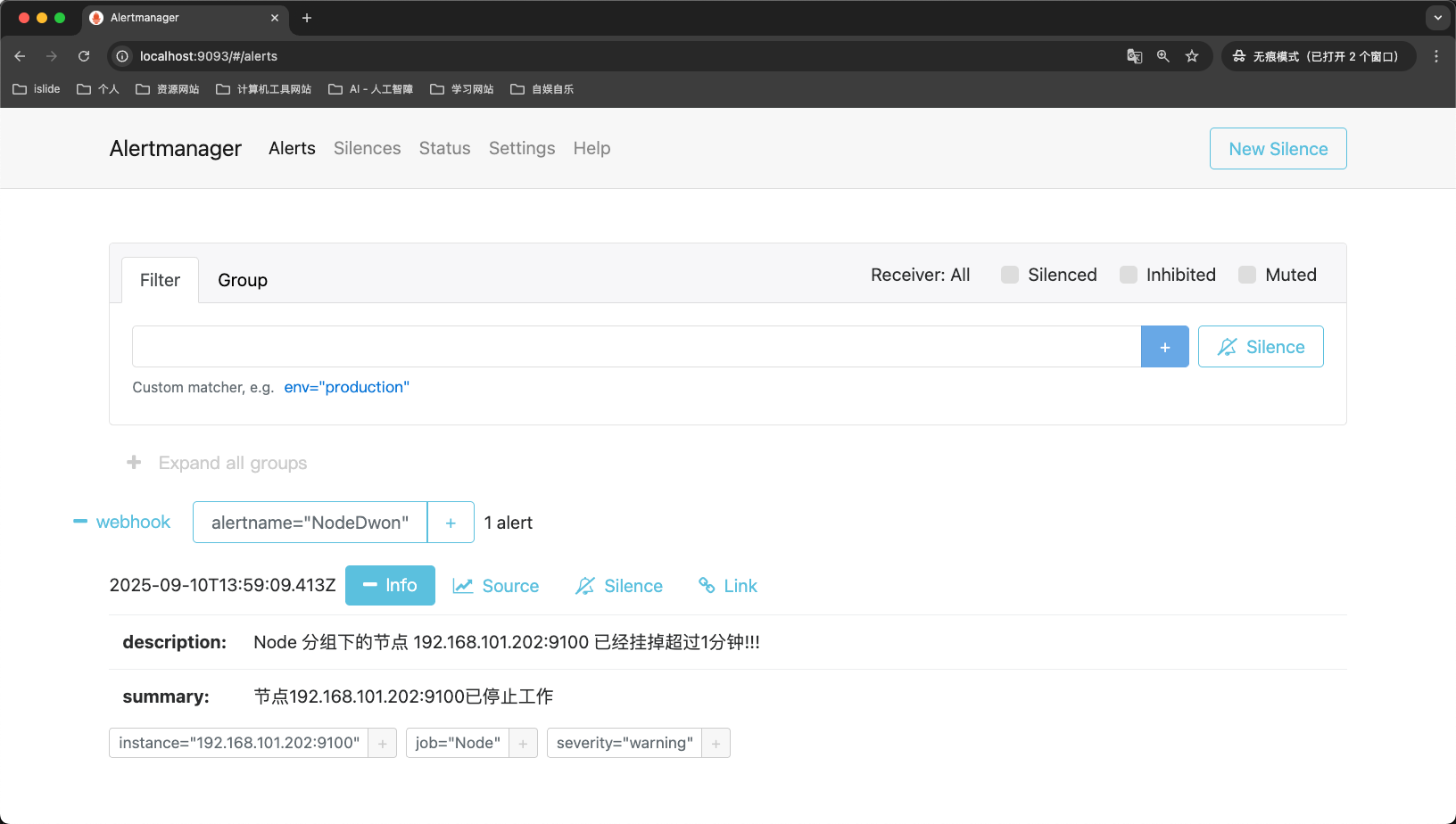
我们再查看Alertmanager服务页面,也发现出现了新的告警消息,如下图所示:
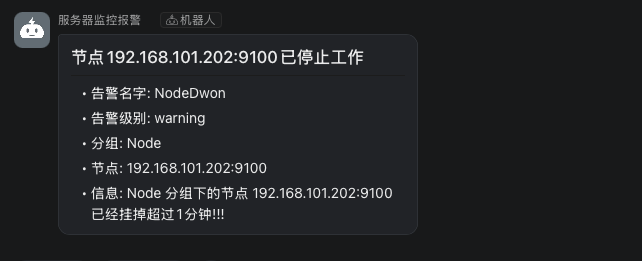
然后我们去查看钉钉消息,已经出现我们定义的告警消息,如下图所示:
五、报警设置
静默通知
当已经知晓通知的时候,可能正在处理问题的时候,就不需要继续告警了,但是告警还在频繁告警,这个时候我们就可以设置静默通知。
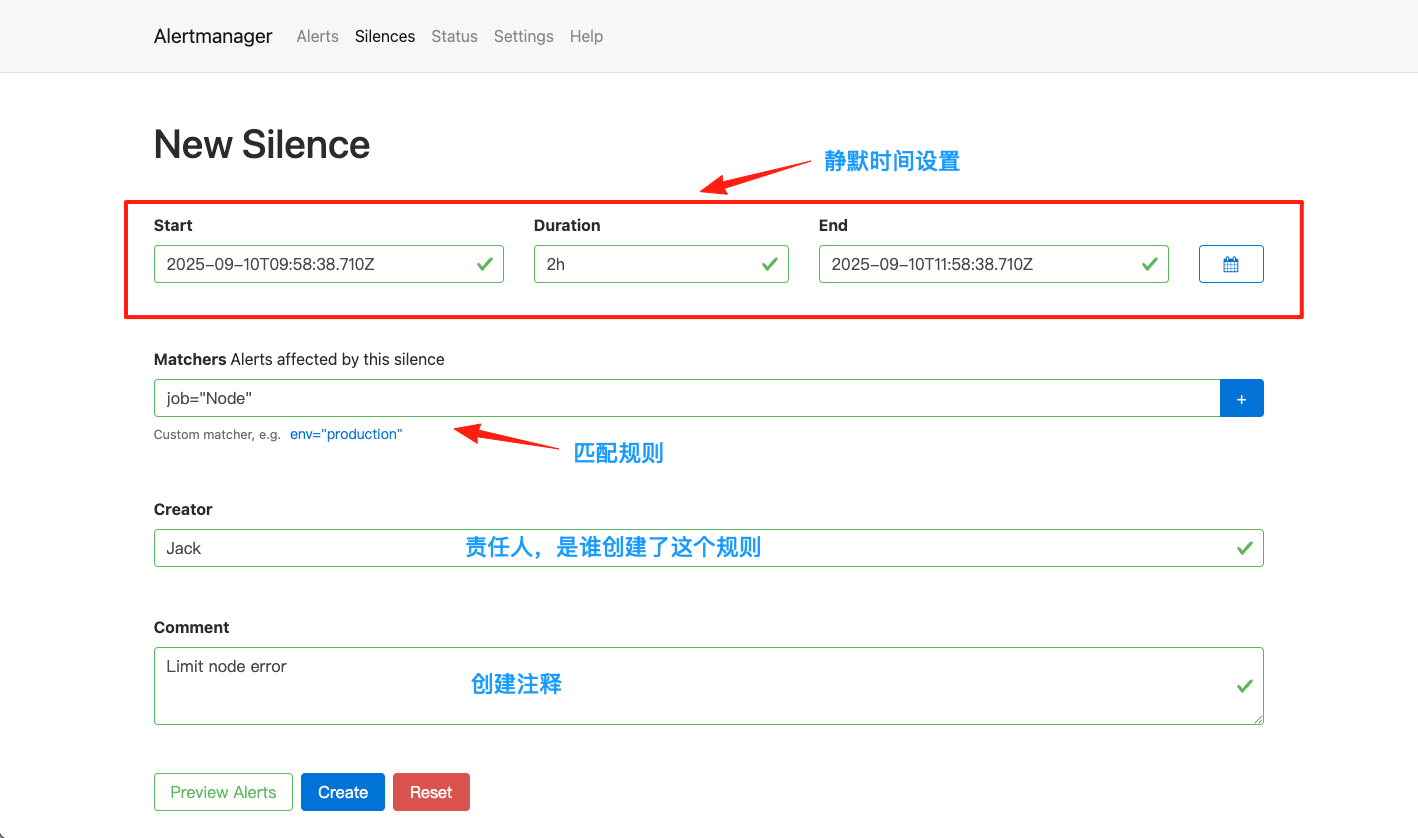
我们可以在Alertmanager服务页面点击New Silence新加静默设置,如下图所示:
创建成功之后我们可以在下图页面看到创建的静默设置,如下图所示:
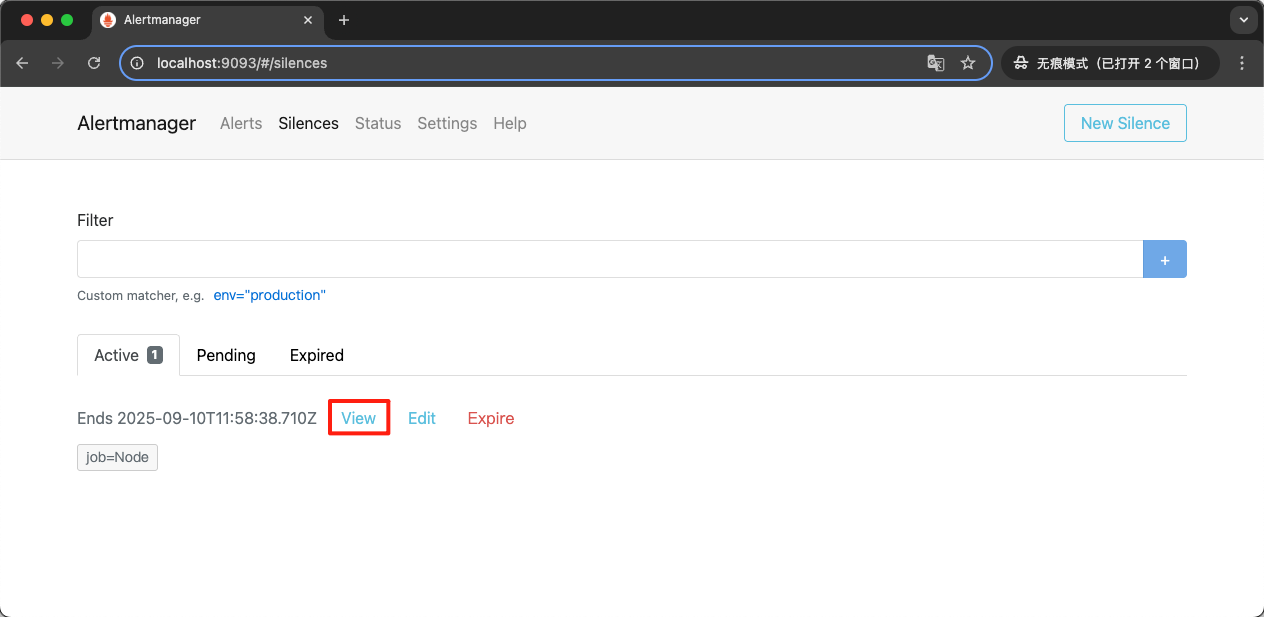
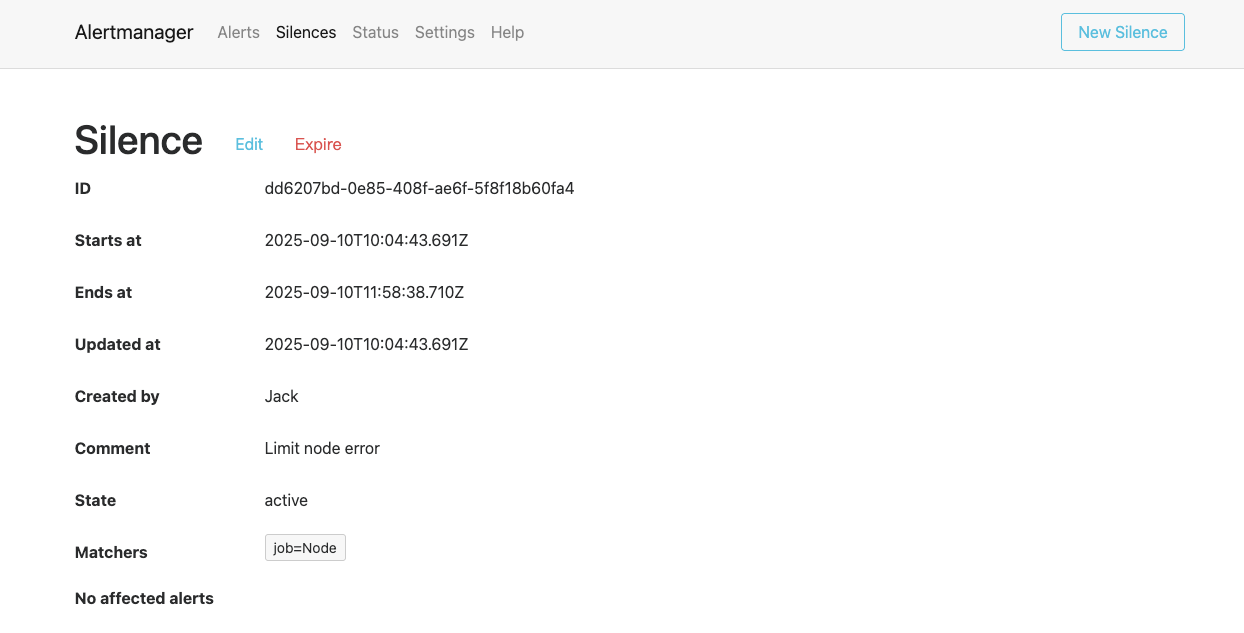
点击查看具体的设置信息,我们设置 job=Node 的标签,则表示具有这个标签的报警在2小时内都不会触发报警,如下图所示:
抑制
抑制是指当某次告警发出后,可以停止重复发送由此告警引发的其他告警的机制。抑制机制可以控制告警通知的行为,能够有效的防止告警风暴。比如:有一台服务器宕机了,上面跑了很多服务都设置了告警,那么肯定会收到大量无用的告警信息,我们可以使用抑制机制来关闭无用报警。
如何使用抑制机制:
使用抑制规则,需要在 Alertmanager 配置文件中的 inhibit_rules 属性下面进行定义source_match或source_match_re、target_match或target_match_re、equal设置。
抑制设置的规则:
当已经发送的告警通知匹配到 target_match 和 target_match_re 规则,当有新的告警规则如果满足 source_match 或者 source_match_re 的匹配规则,并且已发送的告警与新产生的告警中 equal 定义的标签完全相同,则启动抑制机制,新的告警不会发送。
【示例】我们编写两个报警规则,分别是NodeDown和ServiceDown,当节点宕机,由于节点宕机也会导致服务检测不可用,则不报服务不可用的告警。
规则内容如下:
groups:
- name: node-alerts
interval: 30s
rules:
- alert: NodeDown
expr: up == 0
for: 1m
labels:
severity: critical
annotations:
summary: "节点 {{ $labels.instance }} 宕机"
description: "节点 {{ $labels.instance }} (job={{ $labels.job }}) 已经宕机超过1分钟。"
- alert: ServiceDown
expr: up{job="webapp"} == 0
for: 2m
labels:
severity: warning
team: app
annotations:
summary: "服务 {{ $labels.instance }} 不可用"
description: "Web应用 {{ $labels.instance }} 超过2分钟不可访问。"
抑制规则配置:
inhibit_rules:
- source_match:
alertname: NodeDown # 来源告警:节点宕机
severity: critical
target_match:
alertname: ServiceDown # 目标告警:服务不可用
severity: warning
equal:
- instance # 必须是同一个实例才触发抑制
当集群中的某一个主机节点异常宕机导致告警NodeDown被触发,同时在告警规则中定义了告警级别 为 severity=critical,由于主机异常宕机,则该主机上部署的所有服务会不可用并触发报警,根据抑制规则的定义,如果有新的告警级别为 severity=warning,并且告警中标签instance的值与NodeDown告警的相同,则说明新的告警是由NodeDown导致的,则启动抑制机制停止向接收器发送通知。