
PromQL教程
初识PromQL
PromQL是什么?
PromQL全名是Prometheus Query Language, 是Prometheus监控系统内置的一种查询语言,用来从Prometheus存储的时序数据中提取信息。比如:可以查询某个指标的当前值(比如 CPU 使用率),计算一段时间内的变化速率(比如网络带宽、磁盘写入速度)以及做聚合统计(比如多台机器的平均内存使用率)等。
什么是指标和数据点?
指标是对系统或服务的某个特定方面进行量化的测量值,比如:服务器的CPU使用率、内存使用率、数据库的连接数等。指标可以反应系统的运行状态,帮助我们了解系统的性能、稳定性、可用性等。
指标数据一般是周期性采集,每次采集到的数据称为一个数据点,如下所示:
{
"metric": "cpu_usage_idle",
"labels": {
"host": "192.168.100.101",
"region": "us-west"
},
"value": 88.6,
"timestamp": 1756969602
}
以上数据点包含字段:
- metric:指标的名称,比如:
cpu_usage_idle表示CPU空闲率。 - labels:用于标识数据点的标签,比如:
host表示主机名,region表示地区。 - value:数据点的值,比如:
88.6表示CPU空闲率为88.6%。 - timestamp:数据点的时间戳,比如:
1756969602表示数据点产生的Unix时间戳。
metric、labels、value、timestamp 四个字段组成了数据点的唯一标识,metric、labels 两个字段组成了指标的唯一标识。
时序数据库TSDB
TSDB的全称是Time Series Database,是一类专门用来存储和查询时间序列数据的数据库。第一个比较知名的开源时序库就是InfluxDB,最近也新出了一个时序库就是VictoriaMetrics。
常见的TSDB: InfluxDB、Prometheus TSDB、TimescaleDB、OpenTSDB
时序数据库TSDB存在的意义:
根据大量数据点的产生,比如:一台服务器每15秒采集一个数据点,一分钟就会有4个,这样算下来一天就有5760个数据点,如果我们有成千上万台服务器,我们的数据点的数据量是非常庞大的,这么大的数据我们要存放在哪里?我们需要一个存放这些大量数据的地方,时序数据库TSDB就正好可以扮演这个角色。
时序数据库TSDB的特点:
- 按时间顺序产生(带时间戳)。
- 数据点通常是(时间戳,指标名称,值)的形式。
- 典型场景:监控指标、IoT 传感器数据、金融行情、日志事件等。
Prometheus也为时序数据查询设计了一种全新的语言 PromQL。PromQL非常流行,很多时序库都会兼容PromQL,比如:VictoriaMetrics、GrepTimeDB等。
PromQL应用场景
PromQL可以用于许多监控场景,如下所示:
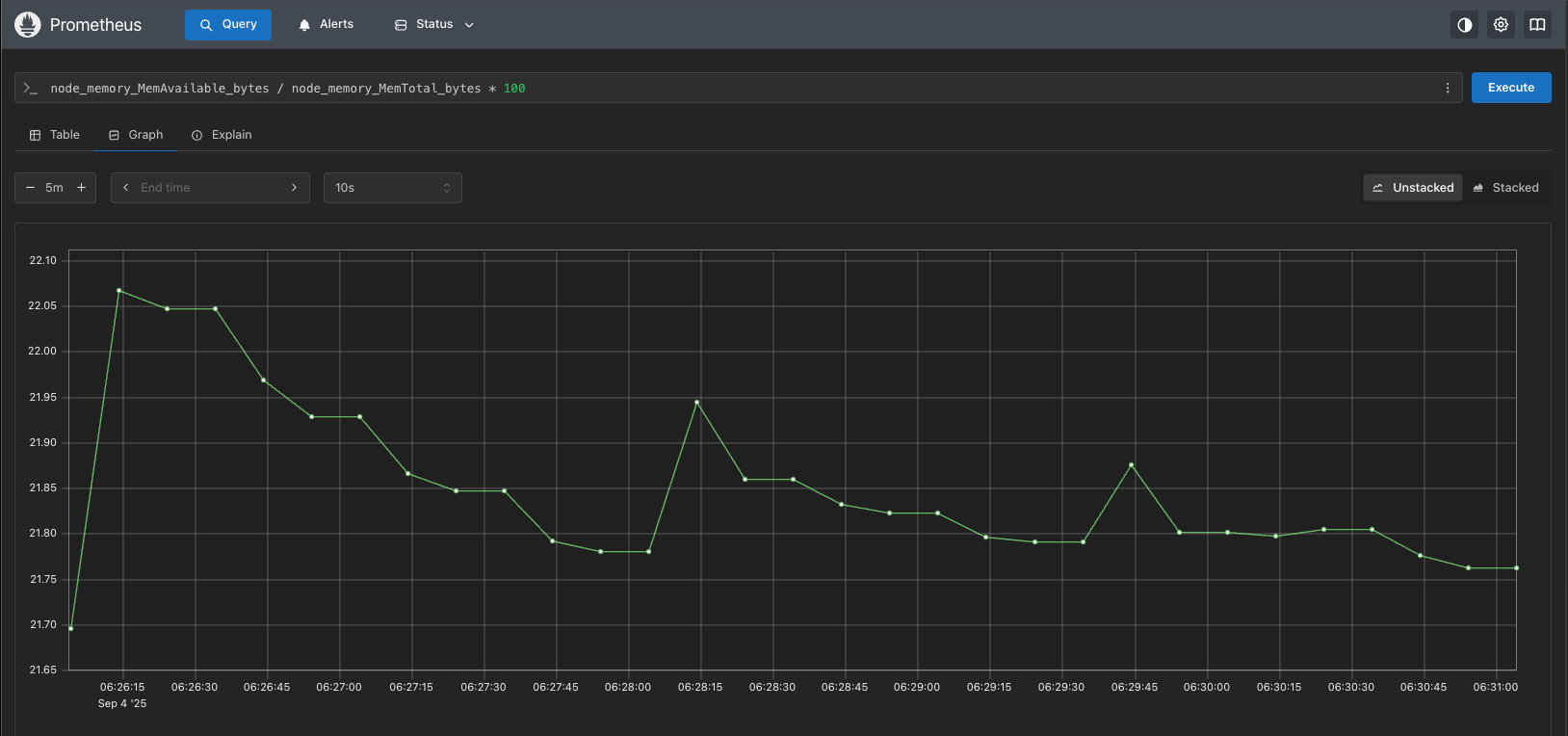
用于临时查询
可以用PromQL来对收集的数据进行实时查询,这有助于我们去调试和诊断遇到的一些问题。一下在Prometheus自带的Graph界面中查询。
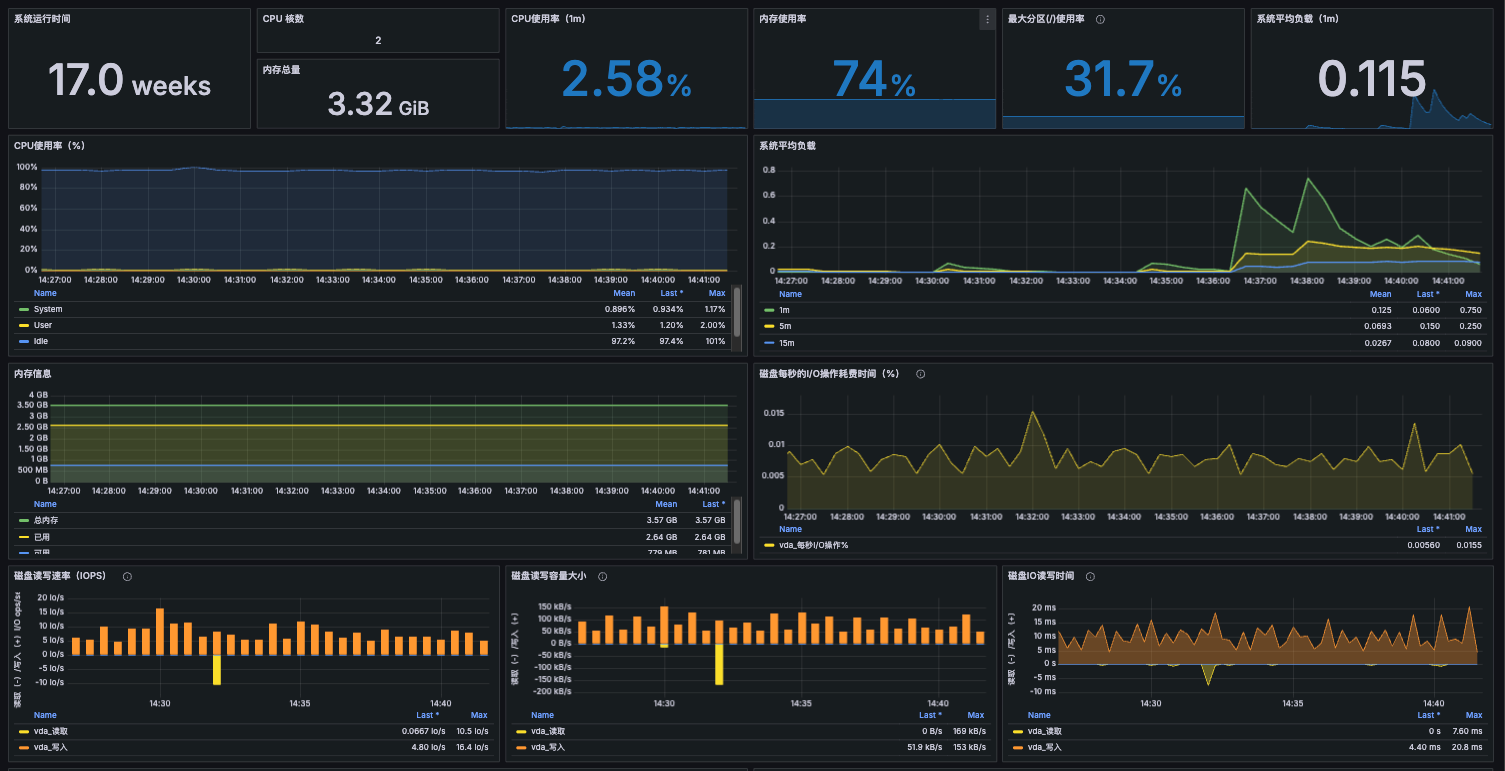
用于图形化仪表盘
也可以基于PromQL查询来创建可视化的图形、表格等面板,如下我们使用Grafana来展示。
用于报警
报警规则核心就是使用PromQL表达式来表示触发报警的条件。示例配置如下:
groups:
- name: DiskAlerts
rules:
- alert: DiskUsageHigh
expr: |
(
node_filesystem_size_bytes{fstype!~"tmpfs|overlay"}
-
node_filesystem_avail_bytes{fstype!~"tmpfs|overlay"}
) / node_filesystem_size_bytes{fstype!~"tmpfs|overlay"} > 0.8
for: 5m
labels:
severity: warning
annotations:
summary: "磁盘使用率超过80%"
description: "实例 {{ $labels.instance }} 的挂载点 {{ $labels.mountpoint }} 使用率超过80%。"
PromQL查询时序数据示例
我们这里使用Prometheus的界面来演示查询,使用node_memory_MemTotal_bytes这个指标名来做一个查询测试,如下图所示:
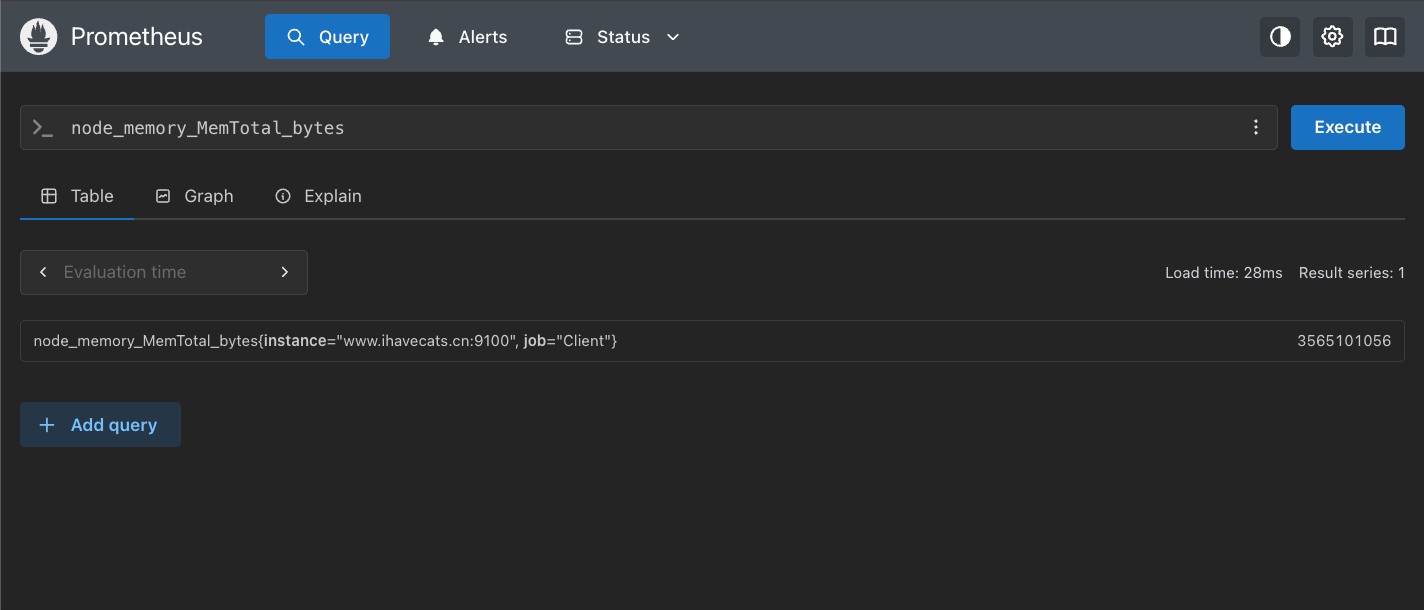
我们使用了node_memory_MemTotal_bytes这个指标,查到了一条数据,意味着你想要查询什么指标,直接输入指标名查询即可,这个操作我们能够在浏览器工具中看到我们的查询调用了/api/v1/query这个接口访问查询数据。
我们直接调用接口查询,请求参数是time和query:
curl -l /api/v1/query?time=1756969602&query=node_memory_MemTotal_bytes
返回内容如下:
{
"status": "success",
"data": {
"resultType": "vector",
"result": [
{
"metric": {
"__name__": "node_memory_MemTotal_bytes",
"instance": "192.168.100.101:9191",
"job": "Client"
},
"value": [
1756969602,
"3565101056"
]
}
]
}
}
返回内容解析:
resultType:查询类型是vector,后面我们做其他查询的时候,注意对比resultType。result:是个数组,包含多个vector,每个vector包含两部分:metric和value。metric:是个对象,包含了指标的标签信息,指标名也放到标签里的,用了一个很特殊的标签名__name__。value:是个数组,第一个值是时间戳,第二个值是结果的值。
补充说明:其中的value的值中有个时间戳是
1756969602,和查询参数的时间戳一样,代表是在这个时间戳的时刻进行采集的数据。
数据15s采集一次为什么能恰巧查询到每一个时间戳的数据?
Prometheus的查询引擎在查询时,会根据查询参数里的时间戳,去找最近的数据点,而不是严格按照时间戳去查找。那也不能无限制一直往前找,最多可以往前找多久,是由Prometheus的启动参数:--query.lookback-delta决定的,默认是 5m,也就是说,你发起查询时,最多只会往前找5分钟的数据。
instant vector和range vector
含义:
- instant vector:瞬时向量,某一时刻(一个时间点)上,每个时间序列的最新样本值,一个时间点,每个时间序列只有一个点。
- range vector:区间向量,某一时间序列在一个时间区间内的一组样本(带时间戳的值),一个时间区间,每个时间序列会包含多个点。
我们可以使用以下方法加上时间范围查询,比如:[1m]代表一分钟,如下图所示:
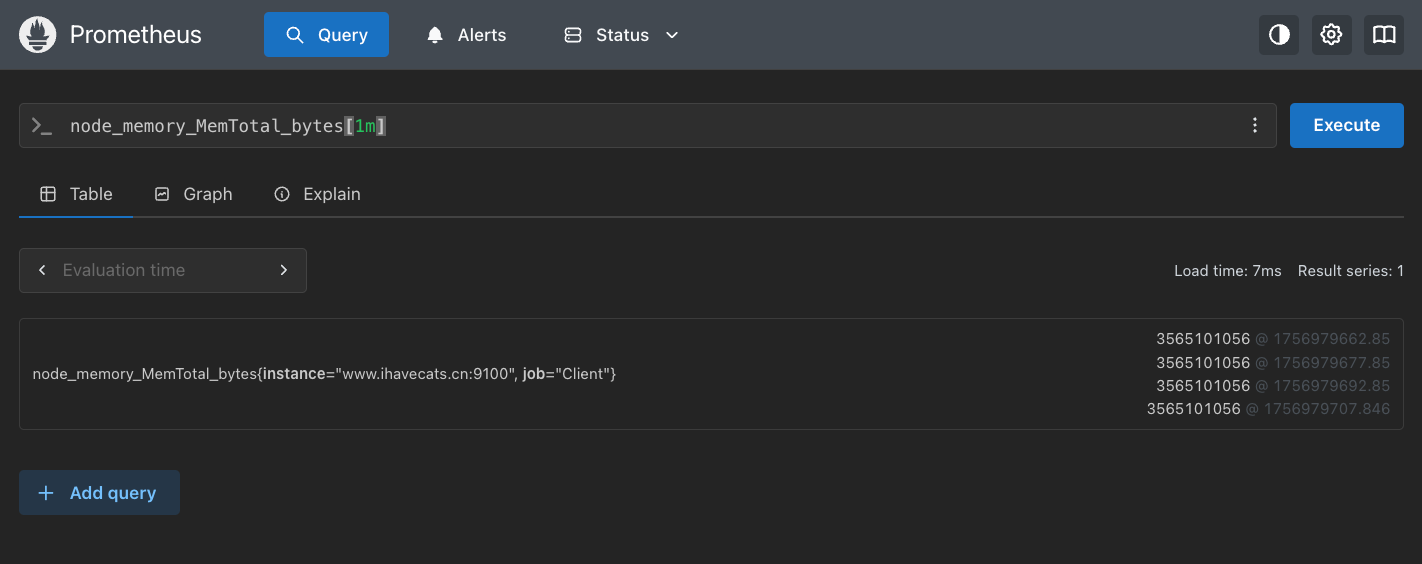
由于数据是每15s采集一次,对于每个指标,一分钟就会出现4个点,我们同样通过查询接口进行查询,在value字段会返回多个时间戳和数值,这里才是时序库中真实存储的数据。
curl -l /api/v1/query?time=1756969602&query=node_memory_MemTotal_bytes[1m]
返回内容如下:
{
"status": "success",
"data": {
"resultType": "matrix",
"result": [
{
"metric": {
"__name__": "node_memory_MemTotal_bytes",
"instance": "192.168.100.101:9191",
"job": "Client"
},
"values": [
[
1756969552.849,
"3565101056"
],
[
1756969567.846,
"3565101056"
],
[
1756969582.848,
"3565101056"
],
[
1756969597.849,
"3565101056"
]
]
}
]
}
}
跟之前的变化:resultType变成了matrix,值的部分变成了一个数组values,values里面是多个value。
query_range
之前的查询只有一个时间戳,我们需要查询一段时间范围内的数据,就需要调用/api/v1/query_range接口。
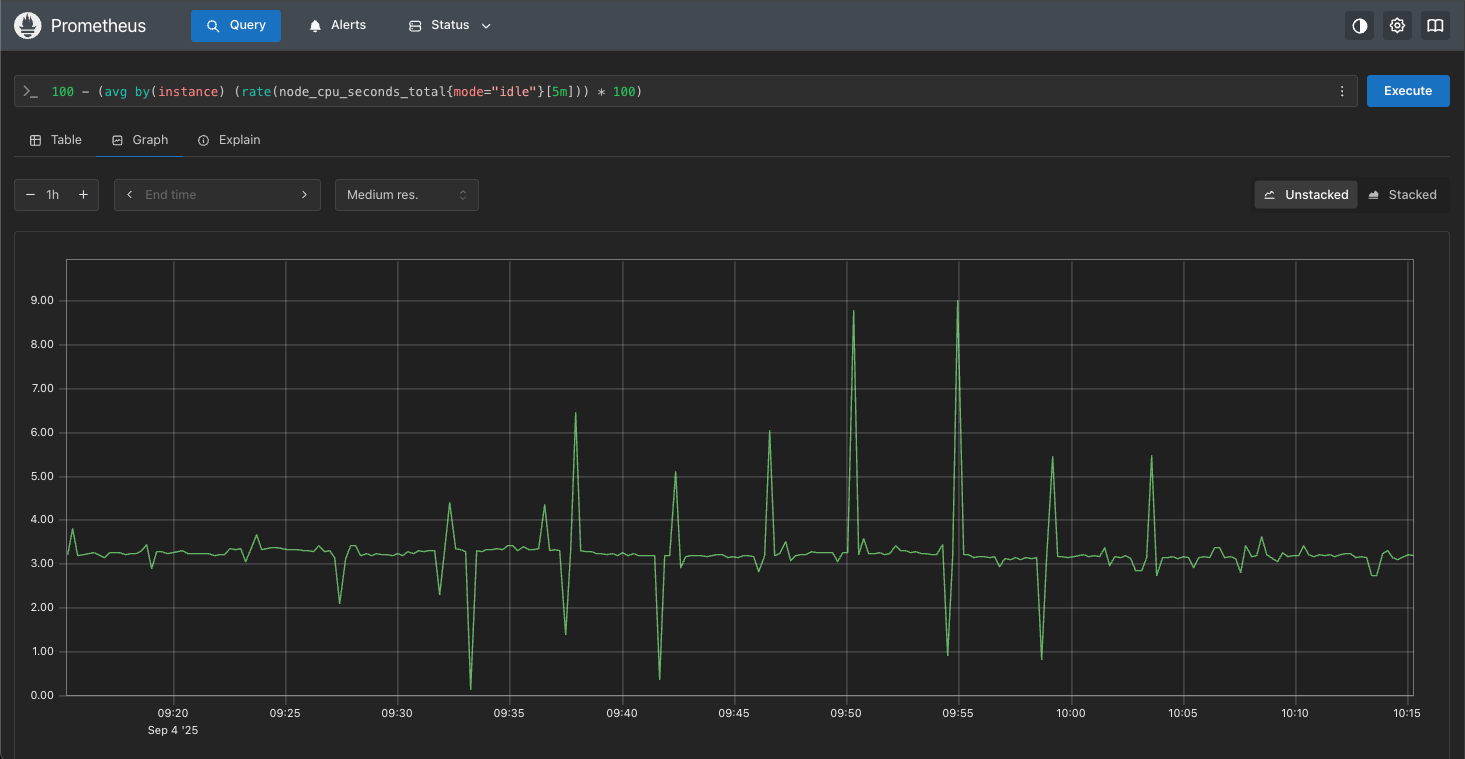
比如我们在使用Graph视图时,不再展示为 Table 了,而是折线图。查到几个指标,就画几条线,发现会调用/api/v1/query_range接口,请求参数是start、end、step、query。
start:查询的开始时间。end:查询的结束时间。step:查询的时间间隔。query:查询的 PromQL语句。
100 - (avg by(instance) (rate(node_cpu_seconds_total{mode="idle"}[5m])) * 100)
查询效果如下图所示:
step参数的含义:
这个参数是用来控制返回的数据点的时间间隔的,比如:step=15,就是每15s返回一个数据点,step=60,就是每分钟返回一个数据点。这个参数的值,会影响到返回的数据点的数量,也会影响到返回的数据点的时间戳。
我们可以把step的参数调整为1s,如下图所示:
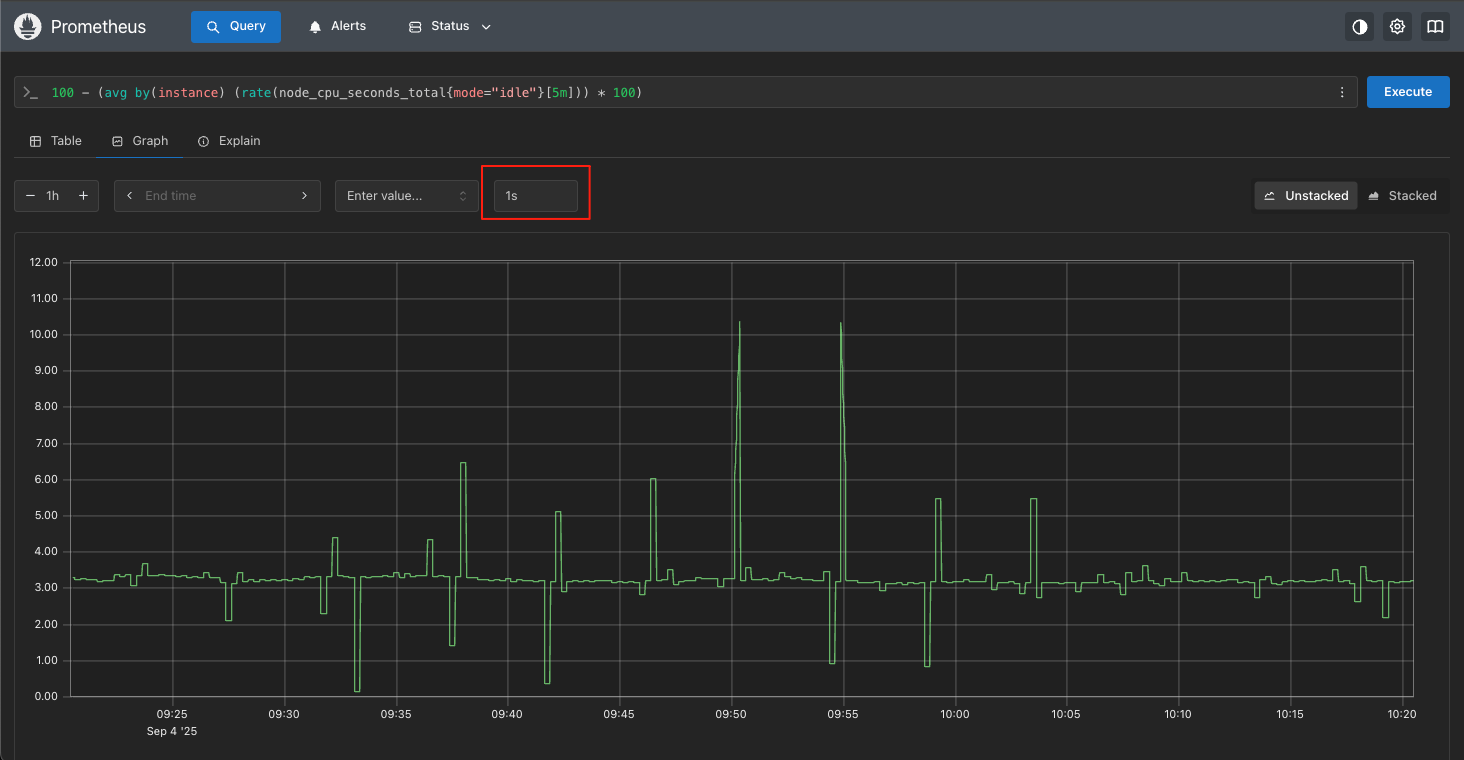
补充说明:可以吧step参数可以理解为监控数据的精确度,数值越小越精确。
Prometheus数据类型
Prometheus 中有四种基本数据类型:Gauge、Counter、Histogram 和 Summary。
Gauge(仪表盘)
表示一个当前的值,瞬时数值,可增可减。
举例说明:
内存或者CPU使用率,刚刚是28%,下一个周期采集的时候又变成了56%。或者内存使用率、正在运行的进程数量等等,都可以用时Gauge类型来表示,当前值对我们来说会非常关注。
Counter(计数器)
单调递增的值,像计数器一样只会增加或在重启时归零。
举例说明:
服务器上某网卡受到的数据包总量,或者操作系统启动为止的活动时间等等,这些都是持续上涨的值我们都可以用Counter类型来表示。
Histogram(直方图)
用来统计样本值的分布情况,也就是用于描述请求延迟、请求大小的分布情况。会把数据按照预定义的 桶(bucket)区间进行计数。
举例说明:
假设我们有一个接口,响应时间大多数在100~300ms,但偶尔会慢到1秒甚至更久。我们想知道95%的请求延迟在多少毫秒以内?是否有异常请求占比突然上升?再比如近一分钟收到 1000 个请求,多少请求是10毫秒内返回?多少请求是100毫秒内返回?多少请求是 1000 毫秒内返回?就是典型的一个需求场景。有了这个数据之后,就可以很方便的计算出99分位的延迟、95分位的延迟这样的数据,相比平均延迟,分位延迟可以更好的描述一个服务的延迟情况。
Summary(概要)
和Histogram类似客户端本地计算分位数,直接上报结果,同时也会提供count和sum。主要描述请求总量、延迟总量、不同的分位数据等。
举例说明:
我们有一个接口,我们想监控请求延迟。我们在代码中埋点一个Summary指标,每次请求都会记录延迟时间,统计请求延迟,并在客户端(应用侧)直接计算分位数,上报3个分位数:P50、P90、P99,误差分别控制在 5%、1%、0.1%。
和Histogram的区别:
- Histogram:只上报分桶数据,分位数需要Prometheus端计算,方便做全局聚合(多实例合并)。
- Summary:直接在客户端算出分位数并上报,不需要 PromQL 的 histogram_quantile()。Summary适合单个服务实例的延迟监控。
- 优点:实现简单,误差可控。
- 缺点:分位数在不同实例之间 不能聚合(例如多台服务的 P99,没法直接合并计算)。
一句话总结就是:Summary就像你在应用里自己算好了[中位数、90 分位、99 分位],直接报给Prometheus;而Histogram是把所有成绩分段上报,再交给 Prometheus帮你算。
PromQL查询语法
按照指标查询
最简单的PromQL就是直接选择具有指定指标名称的序列,如下所示:
node_memory_MemTotal_bytes
该查询将返回许多具有相同指标名称的序列,但有不同的标签组合instance、job、method、path和status等。
选择查询器
瞬时向量选择器
典型额选择器的匹配过滤方式,比如:job="Cient",job="prometheus"之类的。
PromQL支持的四类过滤写法:
=:完全匹配,比如:app=""!=:完全不匹配,比如:app!=""=~:正则匹配,比如:app=~"node-.*"!~:正则不匹配,比如:app!~"master-.*"
根据前面我们的查询,大括号也能包含指标名,指标名也是标签,语法格式如下:
# 使用完全匹配
{__name__="node_memory_MemTotal_bytes",job="Client"}
# 使用正则匹配
{__name__="node_memory_MemTotal_bytes",job=~"Cli.*"}
区间向量选择器
我们只需要在瞬时向量选择器的后面附加一个[<数字><单位>]就可以将瞬时向量变成区间向量,如下所示:
node_memory_MemTotal_bytes[5m]
可以使用的有效时间单位:
ms:毫秒s:秒m:分钟h:小时d:天y:年
offset关键字
offset关键值用于求出同环比数据,比如:当前值相比一周前,是否有巨大变化。
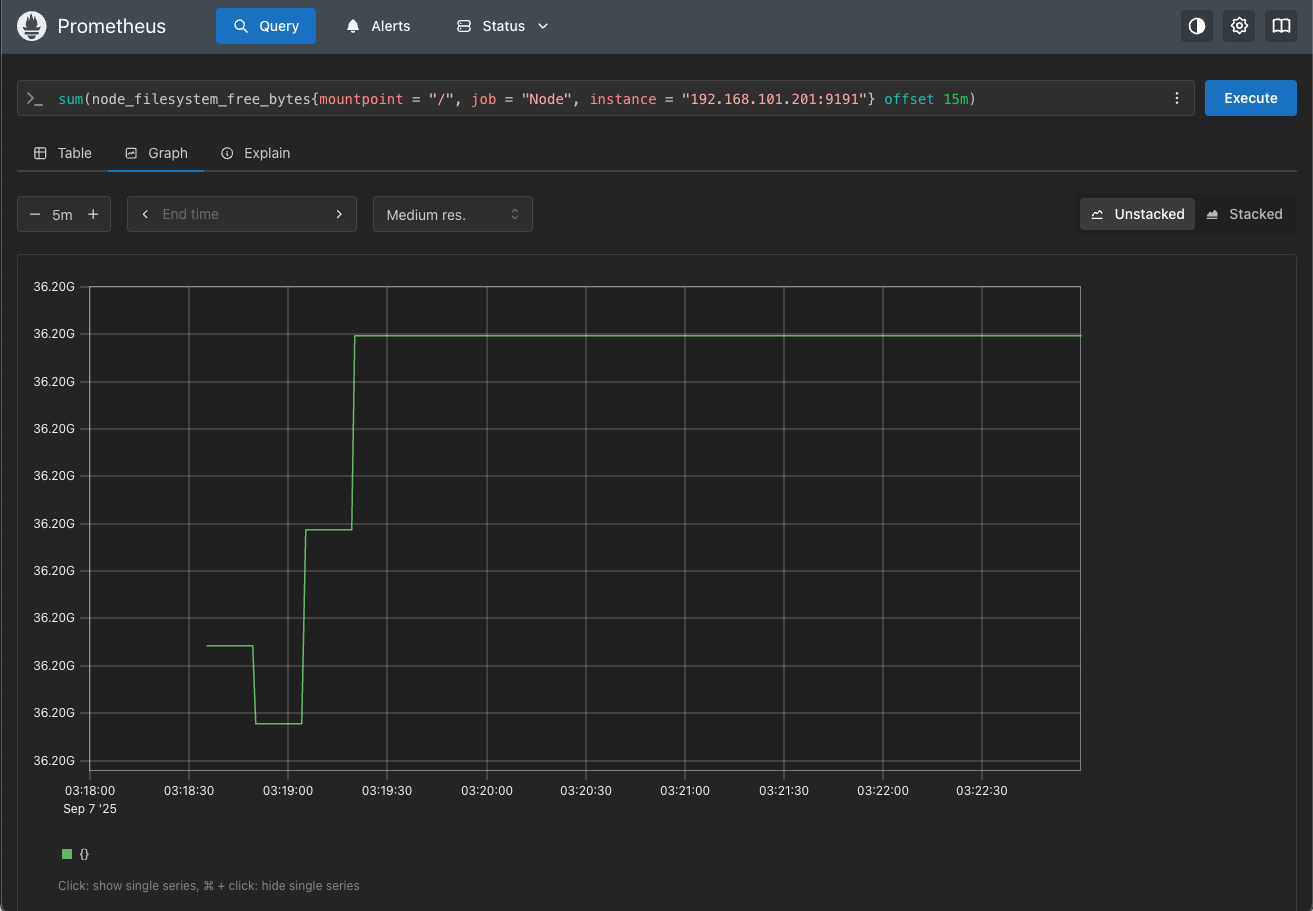
【示例】查看磁盘已使用相比10分钟的同环比
sum(node_filesystem_free_bytes{mountpoint = "/", job = "Node", instance = "192.168.101.201:9191"} offset 15m)
结果如下图所示:
简单聚合
聚合计算就是求出平均值,比如:想计算所有及其的平均内存使用率,或者求出每个CPU的平均使用率等。
使用语法:
聚合查询,求平均值。
avg(查询语句)
group by语法,结果包含某个标签。
avg(查询语句) by (标签名)
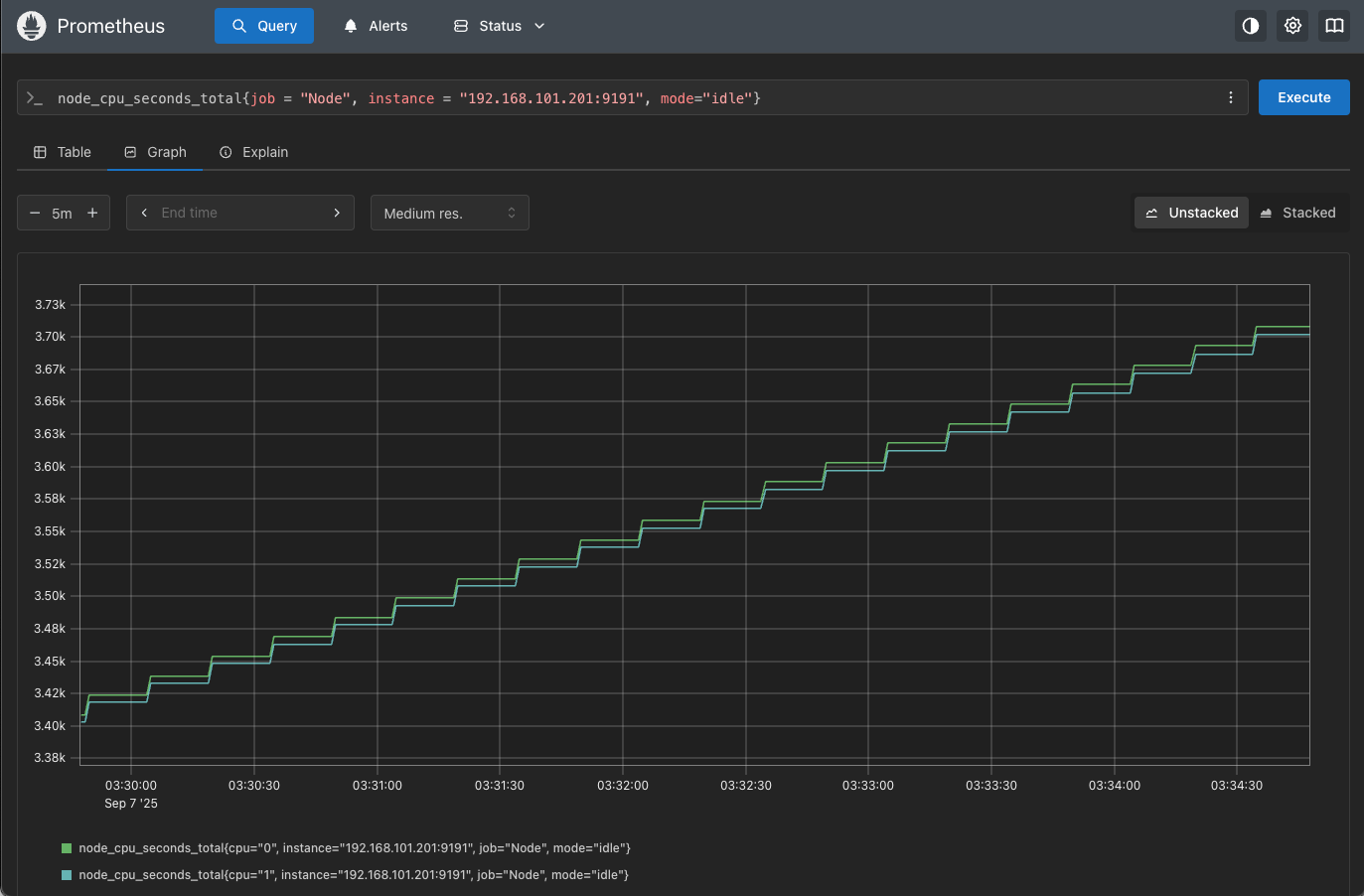
【示例】查询CPU空闲使用时间。
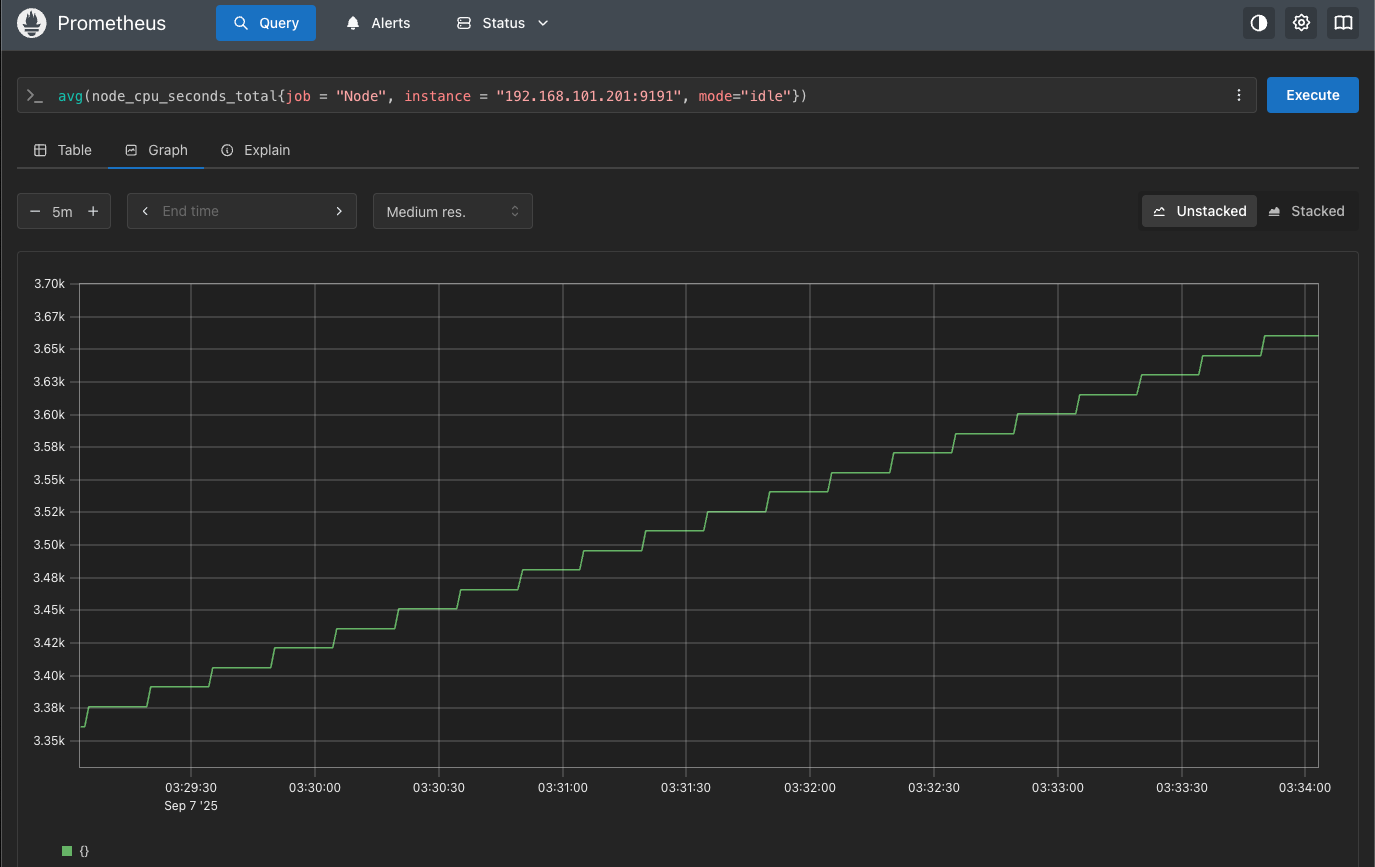
node_cpu_seconds_total{job = "Node", instance = "192.168.101.201:9191", mode="idle"}
默认查询会显示cpu=0和cpu=1两条数据的值,因为服务器配置为2核cpu,如下图所示:
聚合查询,就是求出平均值,比如:我们有两个CPU,普通查询会有两个结果,使用聚合查询会自动求出平均值相当于node_cpu_seconds_total{mode="idle"} / 2。
avg(node_cpu_seconds_total{job = "Node", instance = "192.168.101.201:9191", mode="idle"})
使用聚合查询之后就只会显示他们之间的平均值,就只有一条指标数据了,如下图所示:
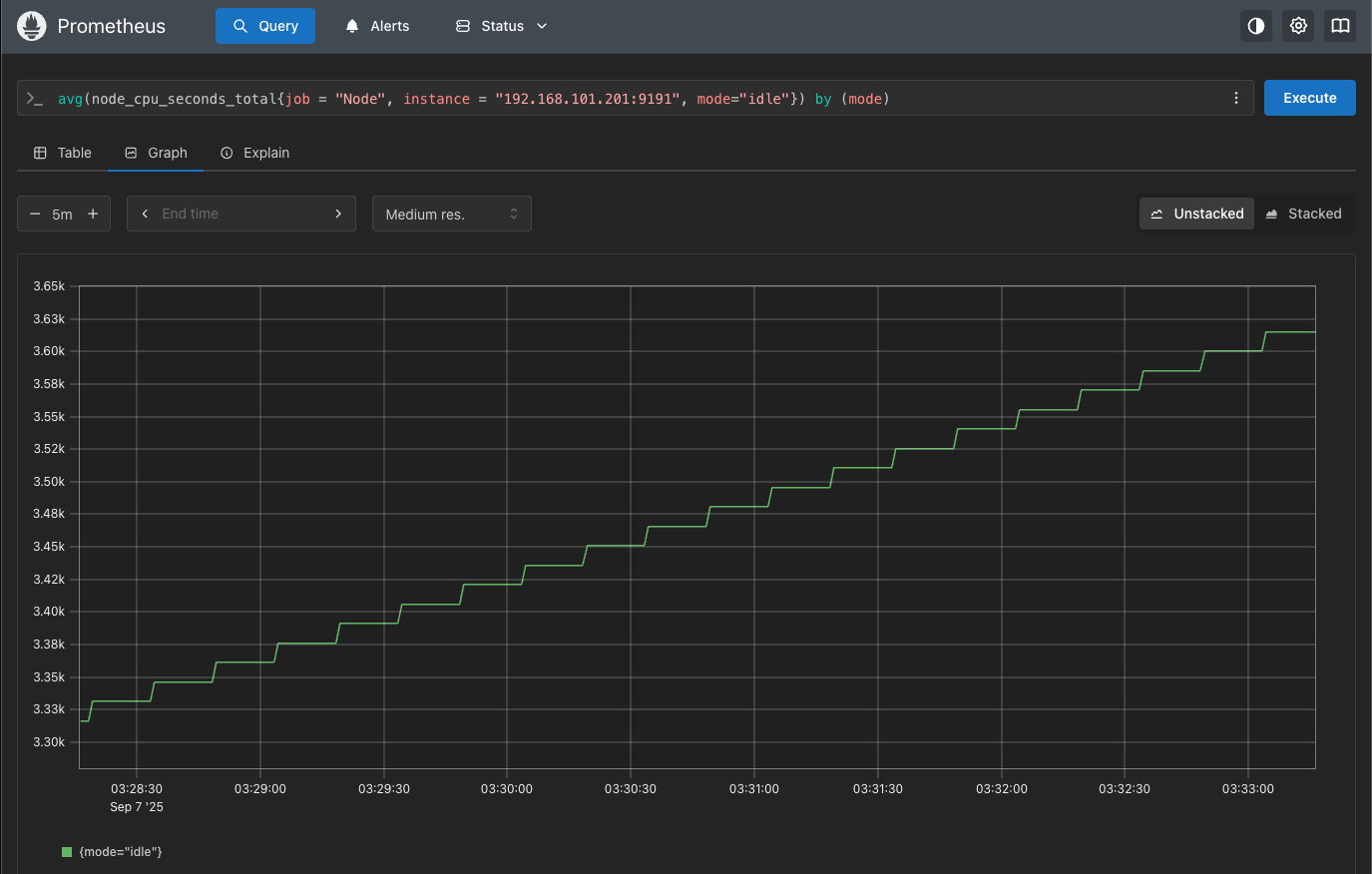
使用group by使结果包含某个标签。
avg(node_cpu_seconds_total{job = "Node", instance = "192.168.101.201:9191", mode="idle"}) by (job)
使用group by之后会在显示结果下面加上添加的标签,如下图所示:
PromQL运算符
算术运算符
算术运算符以下几种:
+:加法(addition),例如-:减法(subtraction),例如node_filesystem_size_bytes - node_filesystem_free_bytes*:乘法(multiplication),例如rate(node_cpu_seconds_total[5m]) * 100/:除法(division),例如node_filesystem_free_bytes / node_filesystem_size_bytes%:取模(modulo),例如up % 2^:冥运算(power/exponentiation),例如2 ^ 3 → 8
【示例】计算每个挂载点的磁盘使用百分比。
(node_filesystem_size_bytes{fstype!~"tmpfs|overlay", job="Node", mountpoint="/"}
- node_filesystem_free_bytes{fstype!~"tmpfs|overlay", job="Node", mountpoint="/"})
/ node_filesystem_size_bytes{fstype!~"tmpfs|overlay", job="Node", mountpoint="/"} * 100
结果如下图所示:
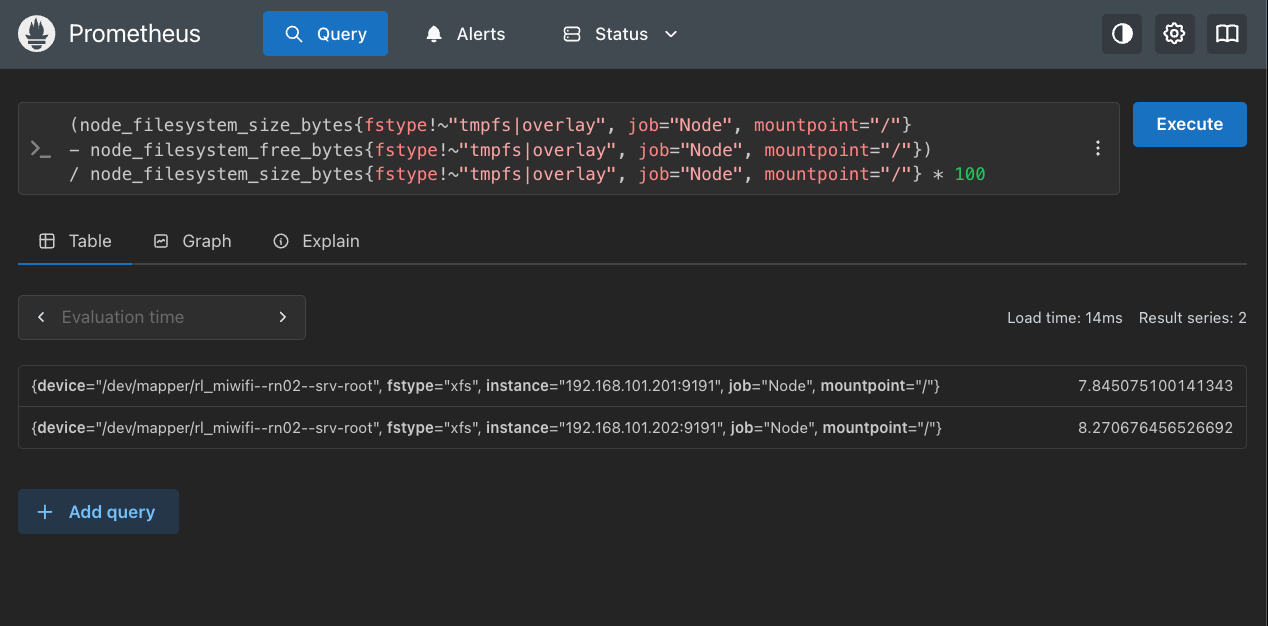
注意:如果分子和分母对应的selector查到的数据标签不同,就没法做除法运算了
比较运算符
比较运算符有以下几种:
==:等于(equal),例如up == 0!=:不等于(not-equal),例如up != 1>:大于(greater-than),例如node_load1 > 1<:小于(less-than),例如node_memory_MemFree_bytes < 1000000000>=:大于等于(greater-or-equal),例如node_filesystem_avail_bytes >= 10737418240<=:小于等于(less-or-equal),例如rate(http_requests_total[5m]) <= 10
【示例】当磁盘可用空间≤ 10GB时触发告警。
node_filesystem_avail_bytes{fstype!~"tmpfs|overlay"} <= 10 * 1024 * 1024 * 1024
常用于告警系统运算使用。
逻辑/集合运算符
相关运算符有以下几种:
and:集合交集,比如在触发告警规则中,两个条件同时都满足才触发。or:集合并集,比如在触发告警规则中,满足其中一个条件就触发。unless:除非,比如在触发告警规则中,除了某种条件否则就触发。
【示例1】只返回存活实例(up==1) 且同时有node_cpu_seconds_total指标的序列。
(up == 1) and (node_cpu_seconds_total)
【示例2】返回宕机实例以及所有node_exporter的版本信息。
(up == 0) or (node_exporter_build_info)
【示例3】返回磁盘大小指标,但排除只读文件系统。
node_filesystem_size_bytes unless node_filesystem_readonly
向量匹配
on和ignoring关键字
在两个向量做运算的时候(比如:+、-、*、/、比较运算等)时,需要确定哪些时序可以匹配。
注意:在默认情况下,两个时序必须所有标签都相同才能匹配。
on关键字
只根据指定的标签对齐,忽略其他标签。
【示例】按照job标签维度来计算错误率。
http_errors_total / on(job) http_requests_total
ignoring关键字
忽略指定的标签进行匹配,其他标签必须相同。
【示例】忽略instance标签,剩下的按照job标签用来对齐。
http_errors_total / ignoring(instance) http_requests_total
group_left和group_right关键字
在确定哪些时序可以匹配时,默认一对一匹配(两个向量的时序必须能一一对应)。一对多时就会报错,使用group_left和group_right关键字再配合on和ignoring关键字就可以放宽规则。
group_left关键字
允许左边的一个时序和右边的多个时序匹配。
【示例】如果你想把按job聚合的结果分发到每个instance上。左边job维度的总数,匹配右边每个带instance的时序。
http_requests_total{job="api"} / on(job) group_left(instance) http_requests_total
group_right关键字
允许右边的一个时序和左边的多个时序匹配。
【示例】想要把每个CPU的指标和每个实例的内存指标结合。右边一个memory 时序,可以匹配左边多个CPU时序。
node_cpu_seconds_total / on(instance) group_right(cpu) node_memory_Active_bytes
变化函数
increase函数
increase()函数用于计算某个Counter类型指标在指定时间范围内的增量(增长的总和)。常用于查看请求总数、错误总数、网络包数的增长等。
【示例】在过去5分钟内,http_requests_total的增长数。
increase(http_requests_total[5m])
rate函数
rate()函数用于计算Counter类型指标在指定时间范围内的平均增长速率(每秒增长值)。
【示例】需要计算node_cpu_seconds_total再最近五分钟内的每秒平均变化率。
rate(node_cpu_seconds_total[5m])
irate函数
irate()函数用于计算Counter的瞬时速率,只用最后两个采样点计算每秒速率,更加敏感,能反映突发流量,但波动大。常用于告警场景,比如突然的QPS峰值等。
【示例】抓取五分钟范围内最后的两个采样点,算出每秒增加了多少请求。
irate(http_requests_total[5m])
聚合函数
sum函数
把多个时序的数值加在一起,求总数。常用于求所有实例的总请求数等。
【示例】求所有实例的总请求数。
sum(http_requests_total)
avg函数
把多个时序的数值加起来再除以数量,求平均数。常用于计算单个cpu的平均使用量等。
【示例】求每个实例所有CPU的平均user时间占比。
avg(node_cpu_seconds_total{mode="user"}) by (instance)
其他函数
prometheus支持的聚合函数:
sum():对聚合分组中的所有值进行求和。min():获取一个聚合分组中最小值。max():获取一个聚合分组中最大值。avg():计算聚合分组中所有值的平均值。stddev():计算聚合分组中所有数值的标准差。stdvar():计算聚合分组中所有数值的标准方差。count():计算聚合分组中所有序列的总数。count_values():计算具有相同样本值的元素数量。bottomk(k, ...):计算按样本值计算的最小的 k 个元素。topk(k,...):计算最大的 k 个元素的样本值。quantile(φ,...):计算维度上的 φ-分位数(0≤φ≤1)。group(...):只是按标签分组,并将样本值设为 1。
直方图函数(histogram_quantile)
直方图是什么?
直方图通常用于跟踪请求的延迟或响应大小等指标值,当然理论上它是可以跟踪任何根据某种分布而产生波动数值的大小。
直方图的概念:
直方图被实现为一组时间序列,每个序列代表指定桶的计数。例如:有多少请求在10ms以下、有多少请求在25ms以下,又有多少请求在50ms以下。
在 Prometheus 中每个bucket桶的计数器是累加的,这意味着较大值的桶也包括所有低数值的桶的计数。在作为直方图一部分的每个时间序列上,相应的桶由特殊的le标签表示。le代表的是小于或等于。
直方图如下图所示:
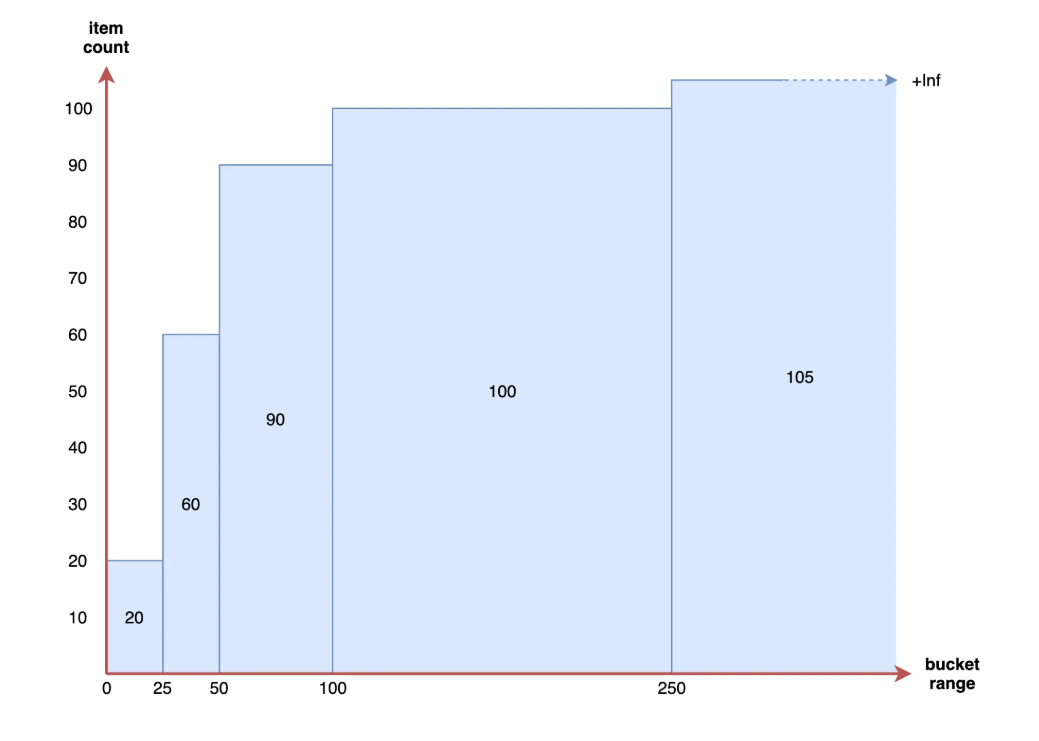
从上图可以看出直方图的计数是累积增加的,直方图可以帮助我们了解这样的问题。比如:我们有多少个请求超过了100ms的延迟?(这需要配置一个以100ms为边界的桶),又比如:我们99%的请求实在多少延迟下完成的?(这类数值被称为百分位数或分位数分位数)。Prometheus中这两个术语几乎是可以通用的。
补充说明:百分位数指定在0-100范围内,而分位数表示在0和1之间,所以第99个百分位数相当于目标分位数0.99。
【示例1】假设应用里有一个指标,http_request_duration_seconds表示接口请求耗时(秒)。数据展开如下:
http_request_duration_seconds_bucket{le="0.1"}
http_request_duration_seconds_bucket{le="0.5"}
http_request_duration_seconds_bucket{le="1"}
http_request_duration_seconds_bucket{le="+Inf"}
http_request_duration_seconds_sum
http_request_duration_seconds_count
计算95分位延迟,意思是过去5分钟内,95%的请求耗时低于多少秒。如下所示:
histogram_quantile(0.95, rate(http_request_duration_seconds_bucket[5m]))
【示例2】计算在0.0001秒内完成的服务API请求的总百分比,与过去5分钟内所有请求总数的平均值。
sum(rate(http_request_duration_seconds_bucket{le="0.0001"}[5m]))
/
sum(rate(http_request_duration_seconds_bucket{le="+Inf"}[5m])) * 100
排序函数
常用的排序函数:
sort():升序函数。sort_desc():降序函数。
【示例1】使用升序函数,把所有实例的请求速率从低到高排序。
sort(rate(http_requests_total[5m]))
【示例2】使用降序函数,把所有实例的请求速率从高到低排序。
sort_desc(rate(http_requests_total[5m]))
检测查询
抓取实例状态(up)
使用up()函数可以抓取实例的状态,1表示抓取正常(实例正常),0表示抓取失败(实例不可用)。如下所示:
up{job="Node"}
【示例1】只显示down掉的实例,通过值等于0来获取。
up{job="Node"} == 0
【示例2】获取挂掉实例的总数。
count by(job) (up{job="Node"} == 0)
检查序列数据(absent)
使用absent()函数用来检测某个时间序列是否不存在。如果存在返回空结果;如果不存在返回一个时间序列,值=1。
【示例】监控某个实例的指标是否丢失。
absent(up{job="Node"})