Kubernetes调度器
Kubernetes调度器了解
Pod调度一般情况下是通过群集的自动调度策略来选择节点调度,默认情况下调度器考虑的是资源足够,并且负载尽量平均。以下的方式可以帮助我们更加细粒度地去控制pod的调度。
在这里我们主要的概念:
- 亲和性和反亲和性:又分为节点亲和性(nodeAffinity)和pod亲和性(podAffinity)。
- 污点和容忍
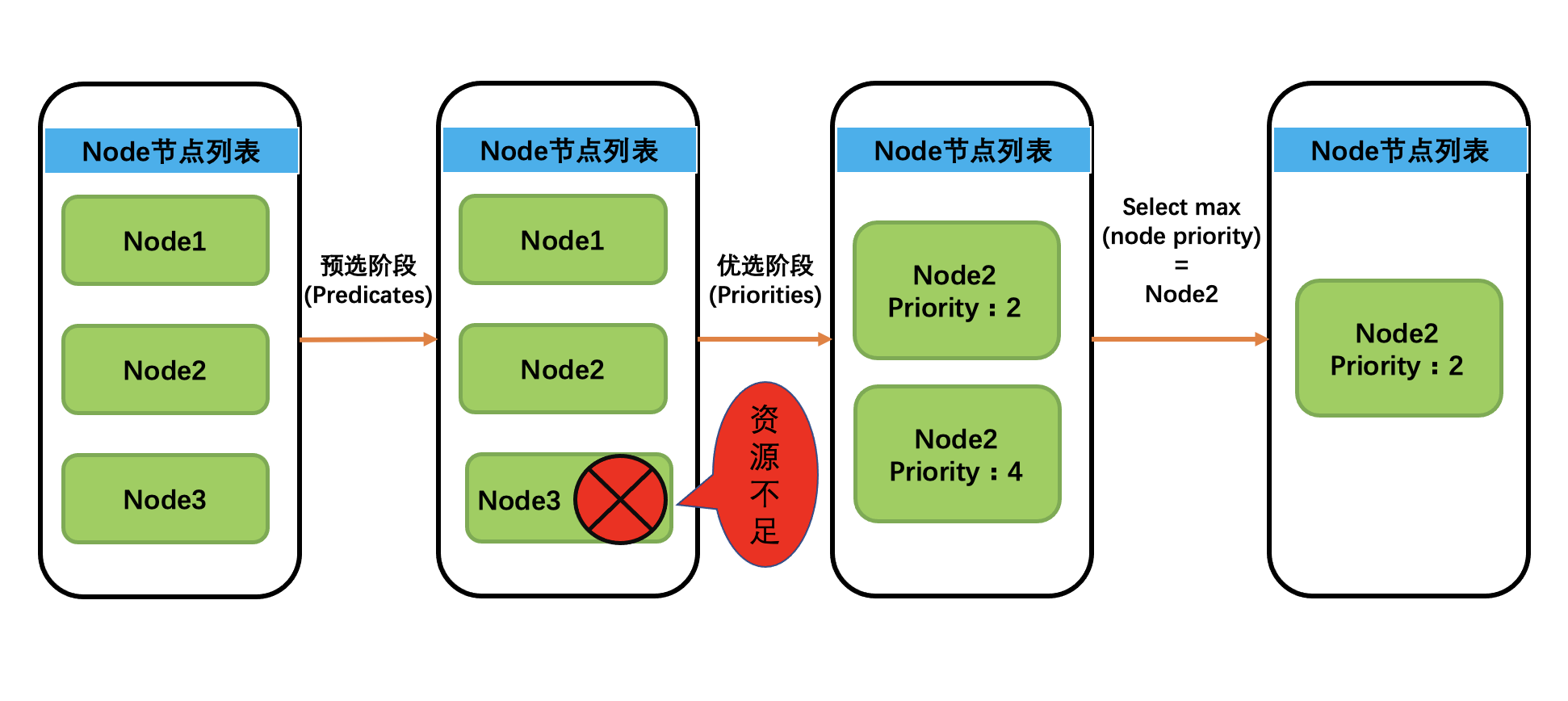
k8s的调度过程的简单示意图,如下图所示:
nodeSelector
nodeSelector是非常常用的调度方式,我们可以使用nodeSelector根据节点的label来进行调度来控制pod的调度。
首先我们先给其中一个节点增加一个标签,并可以通过–show-labels参数查看节点标签。
#给node2节点创建标签
kubectl label nodes node2 name=apptest
#查看节点的标签
kubectl get nodes --show-labels
我们创建一个pod使用nodeSelector来控制他调度到node2节点,资源清单编写如下:
# nodeselector-test.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
app: test-pod
name: test-pod
spec:
containers:
- command:
- sleep
- "3600"
image: busybox
imagePullPolicy: Always
name: test-pod
nodeSelector:
name: apptest
nodeSelector的方式比较直观,但是不够灵活。
亲和性和反亲和性调度
一共分为nodeAffinity(节点亲和性)、podAffinity(pod 亲和性)、podAntiAffinity(pod 反亲和性)。
亲和性调度又分为两种方式:
- 软策略:没有满足调度要求的节点话,pod就会忽略这条规则,继续完成调度过程。设置项的值为preferredDuringSchedulingIgnoredDuringExecution
- 硬策略:如果没有满足条件的节点的话,就不断重试直到满足条件为止。设置项的值为requiredDuringSchedulingIgnoredDuringExecution
节点亲和性
主要是用来控制pod要部署在哪些节点上,以及不能部署在哪些节点上的,它可以用一些简单逻辑进行组合使用。
下面是节点亲和性列举的配置项,需要在spec下配置,需和containers配置项对齐,如下所示:
affinity:
nodeAffinity:
# 硬策略,不调度到标签为kubernetes.io/hostname=master1的节点
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: NotIn
values:
- master1
# 软策略,尽量调度到标签为name=apptest的节点,比重为1进行平均调度
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: name
operator: In
values:
- apptest
现在K8S提供的操作符有下面的几种:
- In:label 的值在某个列表中
- NotIn:label 的值不在某个列表中
- Gt:label 的值大于某个值
- Lt:label 的值小于某个值
- Exists:某个 label 存在
- DoesNotExist:某个 label 不存在
以下是完整的deployment的例子,比如我们让pod不能部署在master节点上,部署在标签为name=apptest的节点上,资源清单编写如下:
# node-affinity-demo.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deploy
namespace: default
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.23.1
ports:
- containerPort: 80
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: NotIn
values:
- master1
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: name
operator: In
values:
- apptest
Pod亲和性
主要用来解决pod可以和哪些pod部署在同一个拓扑域中的问题,这个拓扑域用主机标签实现,可以是单个主机,也可以是多个主机组成,处理的都是pod与pod之间的关系。
下面是pod亲和性列举的配置项,位置和节点亲和性的配置一样,如下所示:
affinity:
podAffinity:
# 硬策略,调度到和标签为app=nginx的pod在同一域里面
# 这里拓扑域为kubernetes.io/hostname值,意思就是同一主机上
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- nginx
topologyKey: kubernetes.io/hostname
# 软策略,调度到和标签为app=tomcat的pod在同一域里面
preferredDuringSchedulingIgnoredDuringExecution:
- podAffinityTerm:
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- tomcat
topologyKey: kubernetes.io/hostname
weight: 1
下面是一个完整的deployment例子,我们通过标签为app=nginx的pod所在的节点,获取该节点标签kubernetes.io/hostname,只要节点标签kubernetes.io/hostname值和标签app=nginx的pod所在节点的标签kubernetes.io/hostname值一样,就可以调度到该节点,再尽量调度到app=tomcat的pod所在节点,资源清单编写如下:
# pod-affinity-demo.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: pod-affinity
namespace: default
spec:
replicas: 2
selector:
matchLabels:
app: pod-affinity
template:
metadata:
labels:
app: pod-affinity
spec:
containers:
- name: pod-affinity
image: busybox
ports:
- containerPort: 80
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- nginx
topologyKey: kubernetes.io/hostname
preferredDuringSchedulingIgnoredDuringExecution:
- podAffinityTerm:
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- tomcat
topologyKey: kubernetes.io/hostname
weight: 1
如果我们删除了标签为app=nginx的所有pod,那么该deployment的所有pod将会一直处于Pending状态,直到标签为app=nginx的pod出现。
Pod反亲和性
反亲和度则是跟上面的亲和度相反,来决定不和哪些pod调度到同一拓扑域里面。
下面是pod反亲和性列举的配置项,位置和节点亲和性的配置一样,如下所示:
affinity:
podAntiAffinity:
# 硬策略,调度到和标签为app=nginx的pod不在同一域里面
# 这里拓扑域为kubernetes.io/hostname值,意思就是不在同一主机上
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- nginx
topologyKey: kubernetes.io/hostname
下面是一个完整的deployment例子,我们通过标签为app=nginx的pod所在的节点,获取该节点标签kubernetes.io/hostname,只要节点标签kubernetes.io/hostname值和标签app=nginx的pod所在节点的标签kubernetes.io/hostname值一样,就不调度到该节点,资源清单编写如下:
# pod-antiaffinity-demo.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: pod-antiaffinity
namespace: default
spec:
replicas: 2
selector:
matchLabels:
app: pod-antiaffinity
template:
metadata:
labels:
app: pod-antiaffinity
spec:
containers:
- name: pod-antiaffinity
image: busybox
ports:
- containerPort: 80
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- nginx
topologyKey: kubernetes.io/hostname
污点和容忍
如果一个节点标记为Taints,除非pod也被标识为可以容忍污点节点,否则该有污点节点就不会被调度 Pod。
比如当我们希望我们的应用服务pod不调度到master节点上去抢占K8S组件的资源,或者把一些特殊资源预留给某些pod,这个时候污点的作用就体现出来了。
污点的策略分类:
- NoSchedule:pod不会被调度到标记有污点的节点上。
- PreferNoSchedule:NoSchedule的软策略,表示尽量不调度到有污点的节点上去。
- NoExecute:一旦Taint 生效,如该节点内正在运行的pod没有对应容忍(Tolerate)设置,则会直接被逐出。
1.污点标记使用
节点标记污点
kubectl taint nodes node2 test=node2:NoSchedule
2.污点的容忍使用
下面是污点的容忍配置项以及参数,位置需要在spec下配置,需和containers配置项对齐,如下所示:
tolerations:
- key: "node-role.kubernetes.io/master"
operator: "Exists"
effect: "NoSchedule"
operator的值:
- Exists:value属性可省略。
- Equal:则表示key与value之间的关系相等。
- 不指定值:则默认值为Equal。
其他两种情况: - key为空,operator为Exists:能容忍所有节点的所有Taints。
- effect为空:匹配所有的effect。
如果需要将pod可以调度到标记为污点的节点上,需要yaml进行容忍声明,资源清单编写如下:
# taint-demo.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: taint-pod
namespace: default
spec:
replicas: 2
selector:
matchLabels:
app: taint-pod
template:
metadata:
labels:
app: taint-pod
spec:
containers:
- name: taint-pod
image: busybox
ports:
- containerPort: 80
tolerations:
- key: "node-role.kubernetes.io/master"
operator: "Exists"
effect: "NoSchedule"
☆Deployment实现DaemonSet功能
资源清单编写如下:
apiVersion: apps/v1
kind: Deployment
metadata:
name: deploy-cp-ds
spec:
replicas: 3
selector:
matchLabels:
app: deploy-cp-ds
template:
metadata:
labels:
app: deploy-cp-ds
spec:
tolerations:
- key: "node-role.kubernetes.io/master"
operator: "Exists"
effect: "NoSchedule"
containers:
- image: nginx:1.23.1
name: deploy-cp-ds
ports:
- containerPort: 80
name: deploy-cp-ds
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values: ["deploy-cp-ds"]
topologyKey: kubernetes.io/hostname
Pod拓扑分布约束
在pod调度的亲和性和非亲和性中主要的两个概念就是堆叠和打散
- :可以将无数个pod都调度到某一个特定的拓扑域中。
- 打散:可以控制一个拓扑域中只存在pod的一个副本。
但是这样的方式不太灵活,比较极端,无法达到很多场景理想的状态。
PodTopologySpread(Pod 拓扑分布约束)就是为了更加精细的控制,提高服务可用性和资源利用率。
注意:PodTopologySpread由EvenPodsSpread特性门所控制,在v1.16版本第一次发布,并在v1.18版本进入beta阶段默认启用。
使用规范
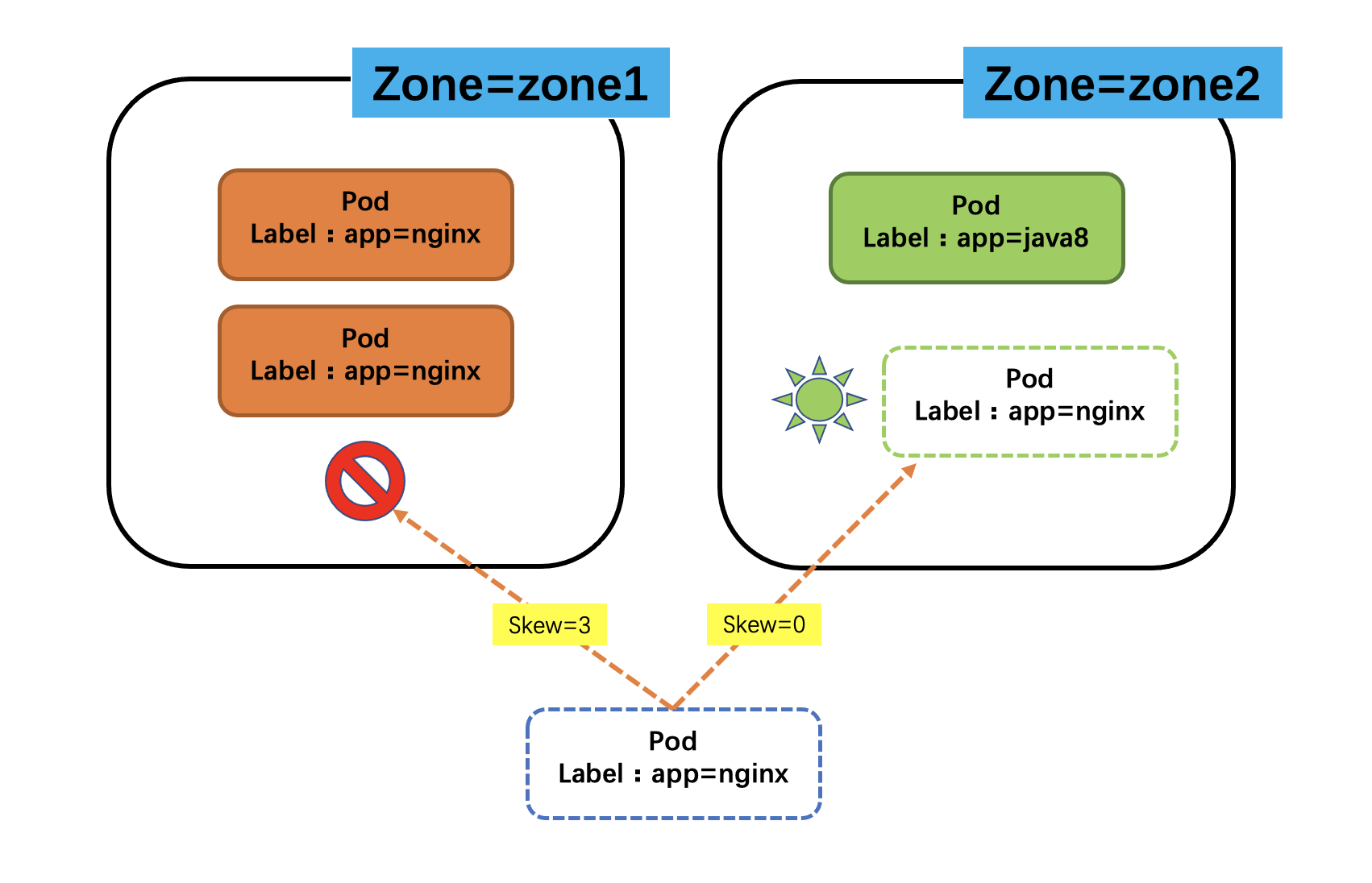
以下是拓扑分布约束的配置项,在Spec下新增了一个topologySpreadConstraints字段即可配置拓扑分布约束,如下所示:
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: zone
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
app: nginx
Deployment、DaemonSet、StatefulSet控制器都能使用这个配置。
如下图所示: